
MariaDB Vector is available on OPEA

I think you’ve come to expect that every collaboration with Intel leads to meaningful, well-executed projects that bring great value to the community. This time, we’re spreading our wings towards empowering enterprises to deploy AI solutions, and we’re excited to show how MariaDB Vector fits into the Open Platform for Enterprise AI (OPEA).
🤖 Open Platform for Enterprise AI
The Open Platform for Enterprise AI, or simply OPEA, is a new sandbox-level project within the LF AI & Data Foundation where Intel plays a pivotal role in its active development and once again it shows its strong commitment to open-source innovation.
OPEA’s mission is to create an open platform project that enables the creation of open, multi-provider, robust, and composable GenAI solutions that harness the best innovation across the ecosystem.
It simplifies the implementation of enterprise-grade composite GenAI solutions, starting with a focus on Retrieval Augmented Generative AI (RAG). The platform is designed to facilitate efficient integration of secure, performant, and cost-effective GenAI workflows into business systems and manage its deployments.
Find more at opea.dev
🚀 Modern microservice approach
OPEA uses microservices to create high-quality GenAI applications for enterprises, simplifying the scaling and deployment process for production. These microservices leverage a service composer that assembles them into a megaservice thereby creating real-world Enterprise AI applications.
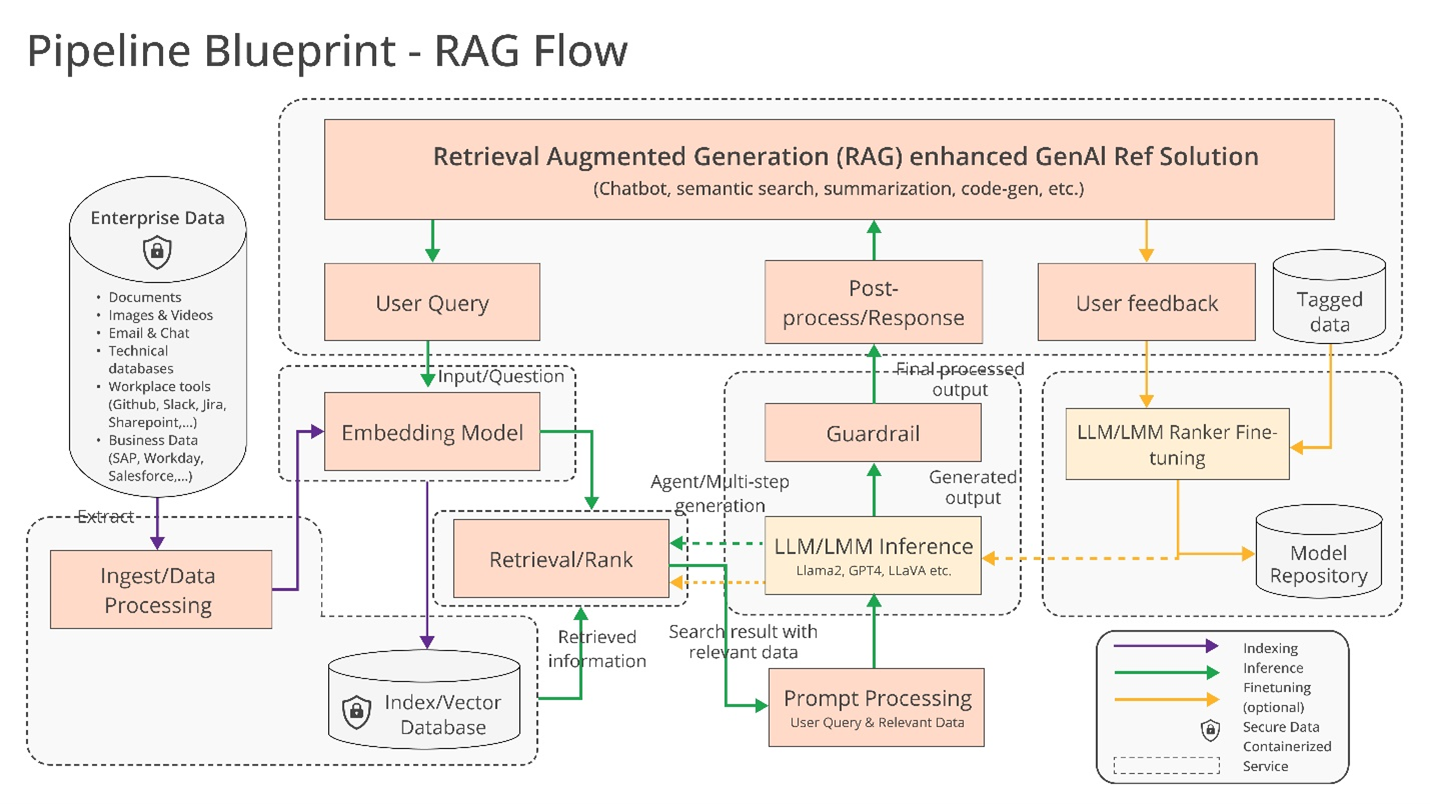
At the heart of a RAG flow sits a vector database as an authoritative knowledge base outside the model’s training data sources.
Of course, the data source won’t be of any use without the services that allow us to interact with it, specifically, services that will allow us to query a vector store and populate it with new documents.
In the next chapter, we’ll explore how MariaDB Vector integrates into this ecosystem by implementing the necessary retrieval / data-preparation components and, the heart of it, the vector store.
🦭 MariaDB Vector integrations
As you may recall from previous blog posts, MariaDB Vector was introduced in MariaDB Server 11.7 and this is the enabler that earned us a seat at the OPEA table.
And I think we’ve earned a good spot with our blazing fast vector. Don’t trust us, trust Mark Callaghan in his benchmark blog post.
Going back to the micro-services architecture, it’s best to explain where we sit by showing a blueprint for a ChatQnA Bot in its simplest form.
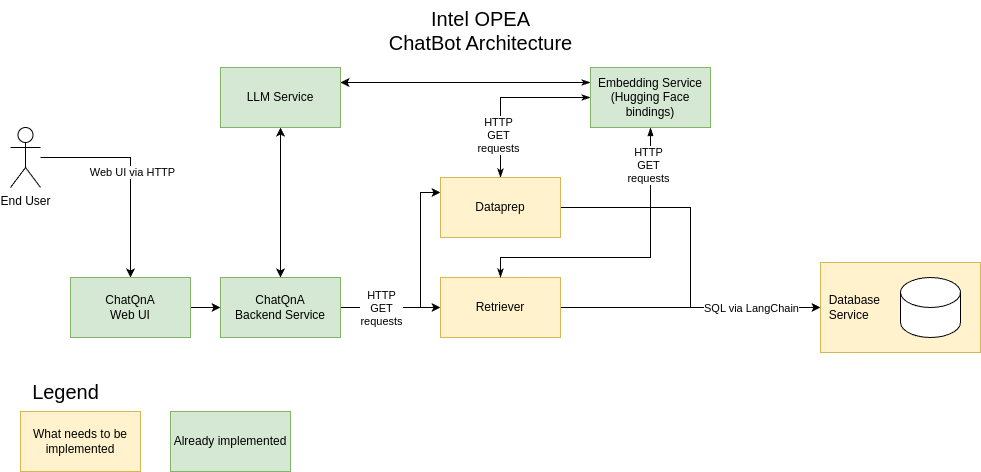
Find on GitHub the code base for all the components.
The user
— Skip this section if you’re familiar with RAG chat bots —
How we help the user? We know that our user will ask questions within a given domain boundaries so we prepare our knowledge base with documents which contain precise information on that matter. The documents are stored into the database (vector store) as vector embeddings by the dataprep service.
The user asks a question (prompt), which is first passed through an embedding model to convert it into a vector embedding. The vector embedding is then used by the retrieval service to perform a similarity search in the vector store, retrieving the most relevant documents.
These retrieved documents are combined with the original question to form an enriched prompt, which is then passed to the language model to generate the answer.
Based on the question and the available documents, the answer can be more accurate, recent and with less hallucinations than using the model alone without augmentation.
The recipe
- Add a MariaDB Vector component to the data preparation service, which is a vector storing abstraction
- Add a MariaDB Vector component to the retrieval service, which is a vector search abstraction
- Deploy a MariaDB Server instance
The first and second services leverage langchain_mariadb python module to interact with the vector store. Langchain provides the necessary abstractions so we don’t think about how we perform a similarity search or how we store an embedding.
For the tech audience here is the implementation of all three services.
— What if you could run the Chat Bot directly on your laptop with just Docker installed? Demo time! —
🔨 Demo
If you want to follow along with me and deploy a Chat Bot, you have two options:
- If you have an Intel Xeon machine in your basement here’s an example.
- Try it on your laptop / workstation using the AIPC example.
I am going with the second option.
At the time of writing this blog-post the AIPC example was not merged yet but you only need two files from the Pull Request, set_env_mariadb.sh and compose_mariadb.yaml
You will need a Hugging Face token and access granted to the model used in this example which is llama3.2
# Clone the repository
git clone https://github.com/opea-project/GenAIExamples
cd GenAIExamples/ChatQnA/docker_compose/intel/cpu/aipc
# Set the Hugging Face API token
export HUGGINGFACEHUB_API_TOKEN=your_token
# Set the default env variables
source ./set_env_mariadb.sh
# Run the services. Will pull the images from DockerHub
docker compose -f compose_mariadb.yaml up -d
By default the web-UI is available at http://localhost:80
Questions time. Say you want to know what was the Nike revenue in 2023.
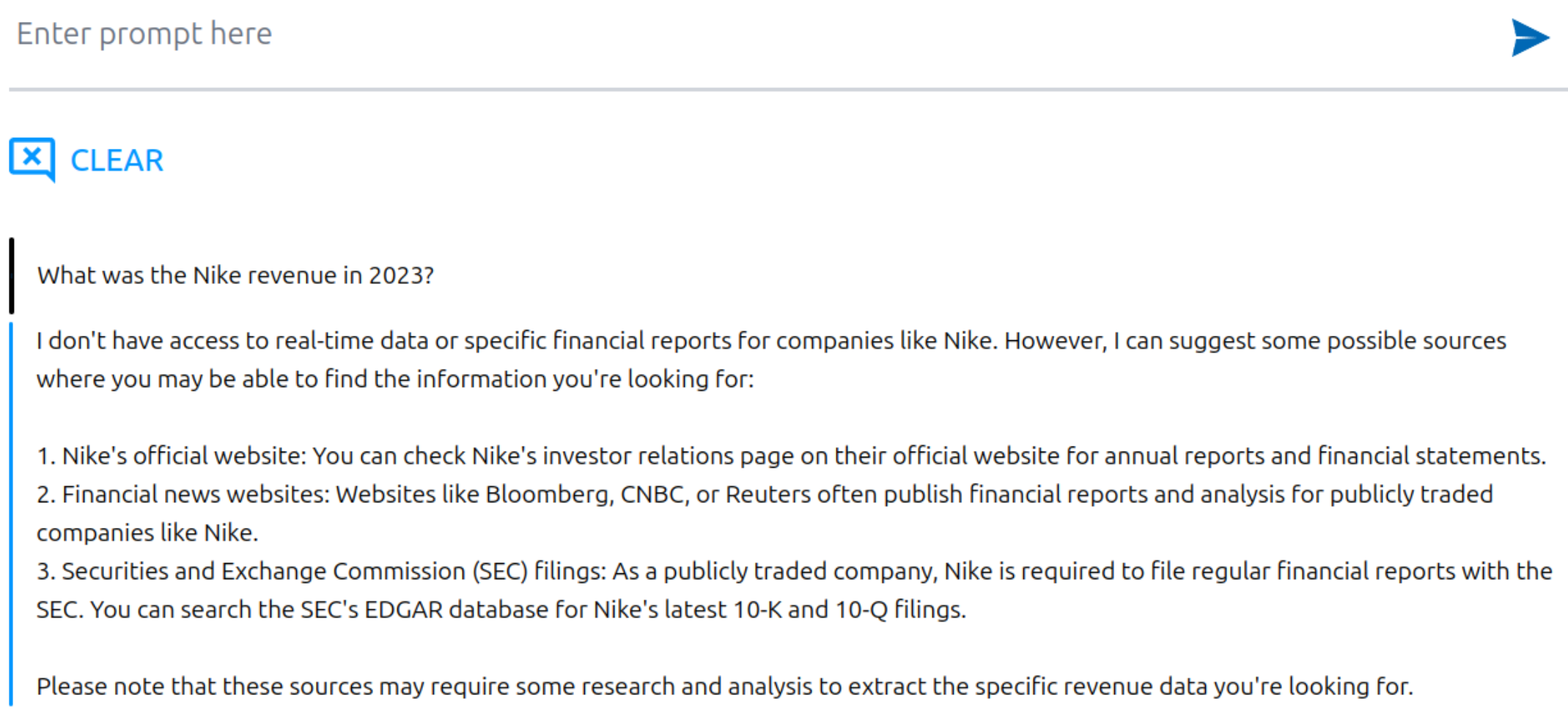
Eh, this wasn’t too helpful. We’re running the stack with an empty vector store.
It’s time to make the model smarter by giving it some context. I am using the top-right upload button to ingest a pdf file containing Nike’s financial status at the end of 2023.
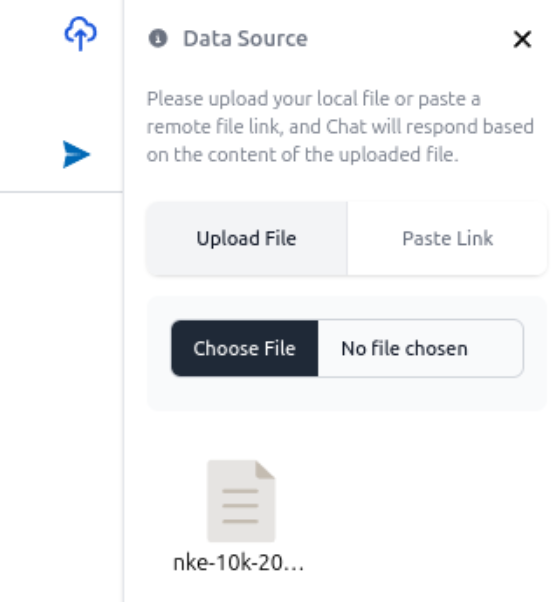
You can check the individual services to see if the file was uploaded successfully.
### dataprep service says it is (status==200)
$ docker logs -f dataprep-mariadb-vector
...
...
opea_dataprep_microservice - [ ingest ] Base mode
INFO: 172.18.0.10:33398 - "POST /v1/dataprep/ingest HTTP/1.0" 200 OK
### the data is present in the vector store
$ docker exec mariadb-server mariadb -uchatqna -ppassword -e "select metadata from vectordb.langchain_embedding limit 1;"
+-----------------------------------------------------+
| metadata |
+-----------------------------------------------------+
| {"doc_name": "uploaded_files/nke-10k-2023 (1).pdf"} |
+-----------------------------------------------------+This time, asking the same question gives an accurate result.

🗒️ Quick recap:
- we’ve cloned the repository
- started the services
- made the model smarter by uploading documents via UI
Simple as that!
🤔 Final thoughts
The power of this framework lies in how easy it is to deploy GenAI solutions.
You’ve already seen it in the demo above. And we haven’t even talked yet about the next big step which is deploying OPEA in a cloud native way via Kubernetes.
Considering the rapid pace of GenAI advancement, the existence of an open-source resource that enables collaborative development of standardized solutions based on best practices is something I am genuinely pleased to see happening.
Thank you for following along, and see you in the next blog post!