
MariaDB Vector part of MariaDB 11.8 LTS. See the latest about vector on the MariaDB Vector project page.
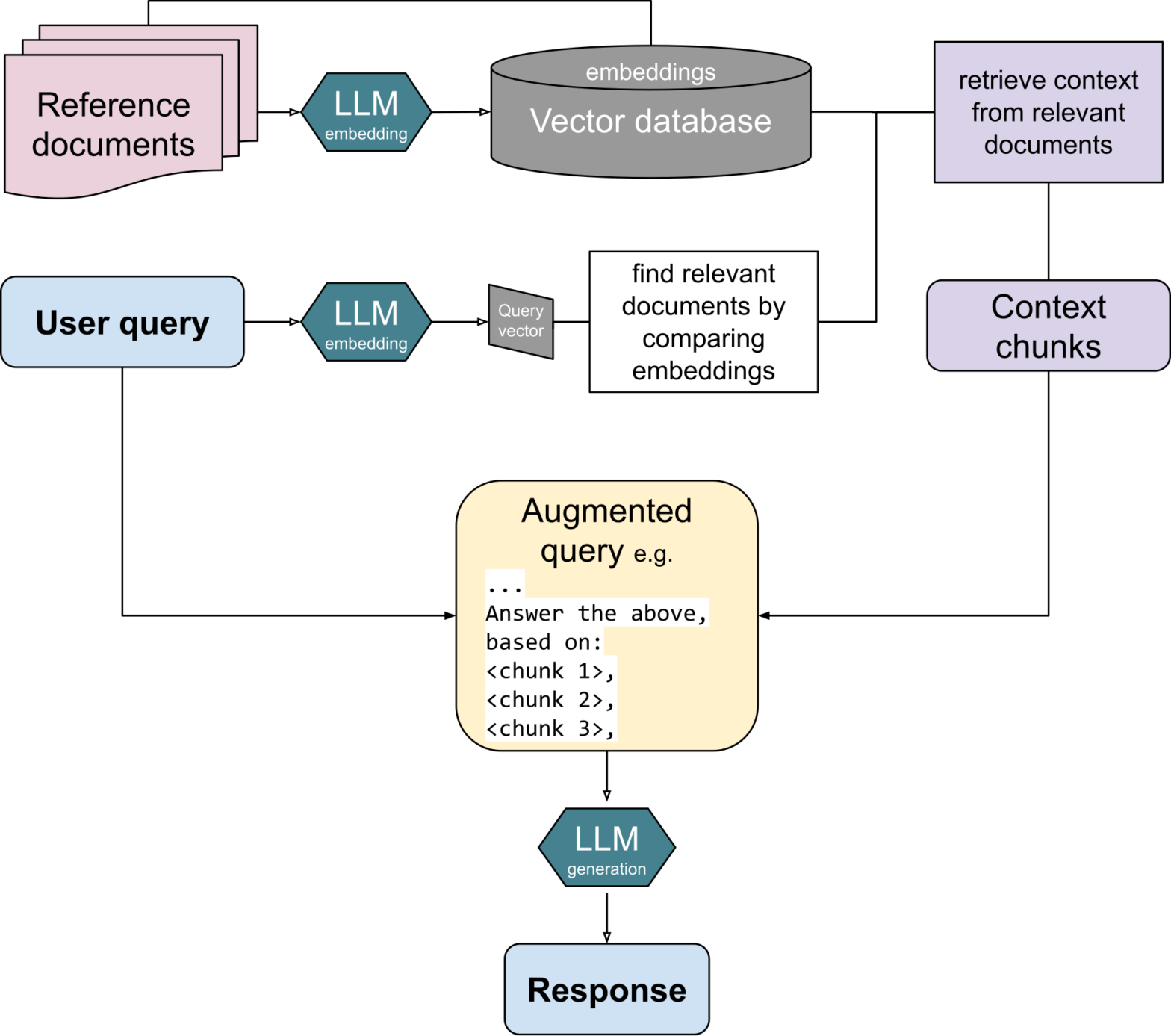
The day has come that you have been waiting for since the ChatGPT hype began: You can now build creative AI apps using your own data in MariaDB Server! By creating embeddings of your own data and storing them in your own MariaDB Server, you can develop RAG solutions where LLMs can efficiently execute prompts based on your own specific data as context.
Why RAG?
Retrieval-Augmented Generation (RAG) creates more accurate, fact-based GenAI answers based on data of your own choice, such as your own manuals, articles or other text corpses. RAG answers are more accurate and fact-based than general Large Language Models (LLM) without having to train or fine-tune a model.
Why RAG with MariaDB?
RAG is now possible with MariaDB’s built-in vector storage and search capabilities. Starting from version 11.7.1, MariaDB uniquely allows users to integrate traditional data queries with vector-based searches within the same database.
To showcase the potential of vectors in MariaDB, I will demonstrate how RAG can be applied to the MariaDB Knowledge Base (https://mariadb.com/kb). The two main steps for RAG that I will go through with code examples are:
- Preparation / vector index creation: each piece of text content is run through an embedding model, and the resulting vectors are inserted into a MariaDB table.
- Running / vector index search:
2.1 When a user inputs a question or a prompt, it is also vectorized with the same embedding model. A nearest neighbour search is performed in MariaDB to find the closest content to the input.
2.2 To generate a response, the user input and the closest content is sent together to a LLM to generate a response for the user.
I’ll now explain RAG with our example code (available on github), with example output at the end.
Preparation / vector index creation
The goal of the preparation in this RAG example is to create a MariaDB table for the content and its vectorized format called embeddings. First you will need to:
- Set up MariaDB 11.7 that includes vector by installing Docker and running
docker run -p 127.0.0.1:3306:3306 --name mdb_117 -e MARIADB_ROOT_PASSWORD=Password123! -d mariadb:11.7-rc - Create an OpenAI API key. Create one at https://platform.openai.com/api-keys and add it to the system variables with
export OPENAI_API_KEY='your-key-here' - Then, to create the table with python, you can use the code below with
CREATE DATABASEandCREATE TABLEstatements. The number in the data typeVECTOR(1536)refers to vector’s dimensions. The “vector length” 1536 is equivalent to OpenAI’s text-embedding-3-small model that we will use.
import mariadb
from openai import OpenAI
import json
import os
conn = mariadb.connect(
host="127.0.0.1",
port=3306,
user="root",
password="Password123!"
)
cur = conn.cursor()
client = OpenAI(api_key=os.getenv('OPENAI_API_KEY'))
def prepare_database():
print("Create database and table")
cur.execute("""
CREATE DATABASE kb_rag;
""")
cur.execute("""
CREATE TABLE kb_rag.content (
title VARCHAR(255) NOT NULL,
url VARCHAR(255) NOT NULL,
content LONGTEXT NOT NULL,
embedding VECTOR(1536) NOT NULL,
VECTOR INDEX (embedding)
);
""")
prepare_database()After preparing the database, create embeddings for your content by sending content to OpenAI’s embedding model and inserting it into the MariaDB table. The code below:
- Reads a jsonl file with over 6000 MariaDB Knowledge Base pages in markdown. The file has been scraped earlier and is provided in the same Github repo with the example code. (By default an excerpt version is selected with 20 KB pages. Change to the “full” file for 6000+ pages.)
- Cuts long pages to shorter “chunks”. This is to fit the embedding model’s max size of 8192 tokens (roughly equivalent to 32 000 characters). In this example pages are split into chunks by header or paragraph to make the content of each chunk more homogeneous which should give it a more accurate vector representation.
- Vectorizes each chunk with OpenAI’s embedding model.
- Inserts the chunk’s content and vector into the database table with an
INSERTstatement. In this example we use MariaDB’sVEC_FromText()to convert a string representation of an embeddingstr(embedding)to the new vector type in MariaDB.
def read_kb_from_file(filename):
with open(filename, "r") as file:
return [json.loads(line) for line in file]
# chunkify by paragraphs, headers, etc.
def chunkify(content, min_chars=1000, max_chars=10000):
lines = content.split('\n')
chunks, chunk, length, start = [], [], 0, 0
for i, line in enumerate(lines + [""]): # Add sentinel line for final chunk
if (chunk and (line.lstrip().startswith('#') or not line.strip() or length + len(line) > max_chars)
and length >= min_chars):
chunks.append({'content': '\n'.join(chunk).strip(), 'start_line': start, 'end_line': i - 1})
chunk, length, start = [], 0, i
chunk.append(line)
length += len(line) + 1
return chunks
def embed(text):
response = client.embeddings.create(
input = text,
model = "text-embedding-3-small" # max 8192 tokens (roughly 32k chars)
)
return response.data[0].embedding
def insert_kb_into_db():
kb_pages = read_kb_from_file("kb_scraped_md_excerpt.jsonl") # change to _full.jsonl for 6000+ KB pages
for p in kb_pages:
chunks = chunkify(p["content"])
for chunk in chunks:
print(f"Embedding chunk (length {len(chunk["content"])}) from '{p["title"]}'")
embedding = embed(chunk["content"])
cur.execute("""INSERT INTO kb_rag.content (title, url, content, embedding)
VALUES (%s, %s, %s, VEC_FromText(%s))""",
(p["title"], p["url"], chunk["content"], str(embedding)))
conn.commit()
insert_kb_into_db()Running / vector index search
When preparing a response to a user’s input, the code below does the following:
- Vectorizes the user’s input. Vectorization needs to be done with the same embedding model as in the preparation.
- Does a nearest neighbour search in MariaDB for the closest content to the user input. In this example we don’t restrict the result to only one “chunk” and instead we fetch the top 5 chunks.
def search_for_closest_content(text, n):
embedding = embed(text) # using same embedding model as in preparations
cur.execute("""
SELECT title, url, content,
VEC_DISTANCE_EUCLIDEAN(embedding, VEC_FromText(%s)) AS distance
FROM kb_rag.content
ORDER BY distance ASC
LIMIT %s;
""", (str(embedding), n))
closest_content = [
{"title": title, "url": url, "content": content, "distance": distance}
for title, url, content, distance in cur
]
return closest_content
user_input = "Can MariaDB be used instead of an Oracle database?"
print(f"User input:\n'{user_input}'")
closest_content = search_for_closest_content(user_input, 5)To generate the actual response to the user input, the below code does the following:
- Prompts OpenAI’s LLM with the user’s input question together with the most relevant content chunks. The prompt also contains instructions for the LLM on how to respond. The prompt is sent as text to OpenAI’s API.
- Prints the LLM response. There is a difference in how the LLM responds with and without the RAG context. The no-context one will tend to hallucinate. The code below prints both responses so we can see the difference.
def prompt_chat(system_prompt, prompt):
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": prompt},
],
)
return response.choices[0].message.content
system_prompt_with_rag = """
You are a helpful assistant that answers questions using exclusively content from the MariaDB Knowledge Base that you are provided with.
End your answer with a link to the most relevant content given to you.
"""
prompt_with_rag = f"""
The user asked: '{user_input}'.
Relevant content from the MariaDB Knowledge Base:
'{str(closest_content)}'
"""
print(
f"""
LLM response with RAG:'
{prompt_chat(system_prompt_with_rag,prompt_with_rag)}'
"""
)
system_prompt_no_rag = """
You are a helpful assistant that only answers questions about MariaDB.
End your answer with a link to a relevant source.
"""
prompt_no_rag = f"""
The user asked: '{user_input}'.
"""
print(
f"""
LLM response without RAG:
'{prompt_chat(system_prompt_no_rag, prompt_no_rag)}'
"""
)Below is the output when running the whole script for the question “Can MariaDB be used instead of an Oracle database?”.
The LLM answer with RAG is factual and on point and provides a source url reliably taken from provided content.
The LLM answer without RAG “fabricates” an answer without much actual content and creates a source url that sounds plausible, but does not exist.
User input: 'Can MariaDB be used instead of an Oracle database?' LLM response with RAG: 'Yes, MariaDB can be used instead of an Oracle database, especially with features like the `SQL_MODE='ORACLE'`, which allows for compatibility with Oracle SQL syntax and behavior. This makes it easier for organizations to migrate applications from Oracle Database to MariaDB while preserving existing SQL scripts and application logic. For more detailed information, you can refer to the following link: [SQL_MODE=ORACLE](https://mariadb.com/kb/en/sql_modeoracle/).' LLM response without RAG: 'Yes, MariaDB can be used as an alternative to an Oracle database in many scenarios, especially for applications that require relational database management. However, it is important to evaluate the specific needs of your application, as there may be differences in features, performance, and compatibility. For more detailed information about the differences between MariaDB and Oracle, you can refer to the official MariaDB documentation here: [MariaDB vs Oracle](https://mariadb.com/kb/en/mariadb-vs-oracle/).'
So that’s the basic idea of RAG with MariaDB. We are looking forward to hearing about more tests and use cases on your own data.
Resources
- The presented code example code and scraped KB in github: https://github.com/MariaDB/demos/mariadb-kb-rag/
- MariaDB Vector Overview: https://mariadb.com/kb/en/vector-overview/
- Installing and Using MariaDB via Docker https://mariadb.com/kb/en/installing-and-using-mariadb-via-docker/
- OpenAI Embeddings https://platform.openai.com/docs/guides/embeddings
- OpenAI Chat Completions https://platform.openai.com/docs/guides/text-generation
- Coding tools used: Cursor (https://www.cursor.com/) with Claude 3.5 Sonnet and Black (https://pypi.org/project/black/)