Tag Archives: LLM
Who says developing MariaDB plugins is hard? I was able to produce one in under 3 minutes!
I of course did it by asking Grok nicely:
The produced result is actually very decent:
/*
errorwatch.c – MariaDB Audit API plugin
Records statement execution errors into a dedicated log file.
This plugin subscribes to the GENERAL audit class and logs
events of type MYSQL_AUDIT_GENERAL_ERROR (and STATUS events
that carry a non-zero error code). It writes structured
entries to /var/log/mariadb/errorwatch.log (or /tmp/ fallback).
To build (inside MariaDB source tree):
1. Copy this file and CMakeLists.txt to plugin/errorwatch/
2. …
Continue reading “Vibe-coding an Audit Plugin in Under 3 Minutes”

Not what AI can do for MariaDB – but what MariaDB can do for AI
I have hinted at this before (This Month in MariaDB – August 2025), but it deserves to be said again: our vision for MariaDB’s role in AI is both clear and ambitious. We do not simply want to participate in the AI space – we aim to be the bridge between real-world data and modern AI systems.
Large Language Models are, at their core, vast read-only neural networks. The data that organisations truly depend upon does not reside inside these models;
…
Continue reading “MariaDB and AI: Building the Bridge That Really Matters”

One week left to join the AI RAG Hackathon with MariaDB Vector and Python!
Winners get to demo at the Helsinki Python meetup in May, receive merit and publicity from MariaDB Foundation and Open Ocean Capital, and prizes from Finnish verkkokauppa.com.
To participate, gather a team (1-5 people) and submit an idea by the end of March for one of the two tracks. You then have until May 5th to develop the idea before the meetup 27th May.
- Integration track: Enable MariaDB Vector in an existing open source project or AI-framework.
…
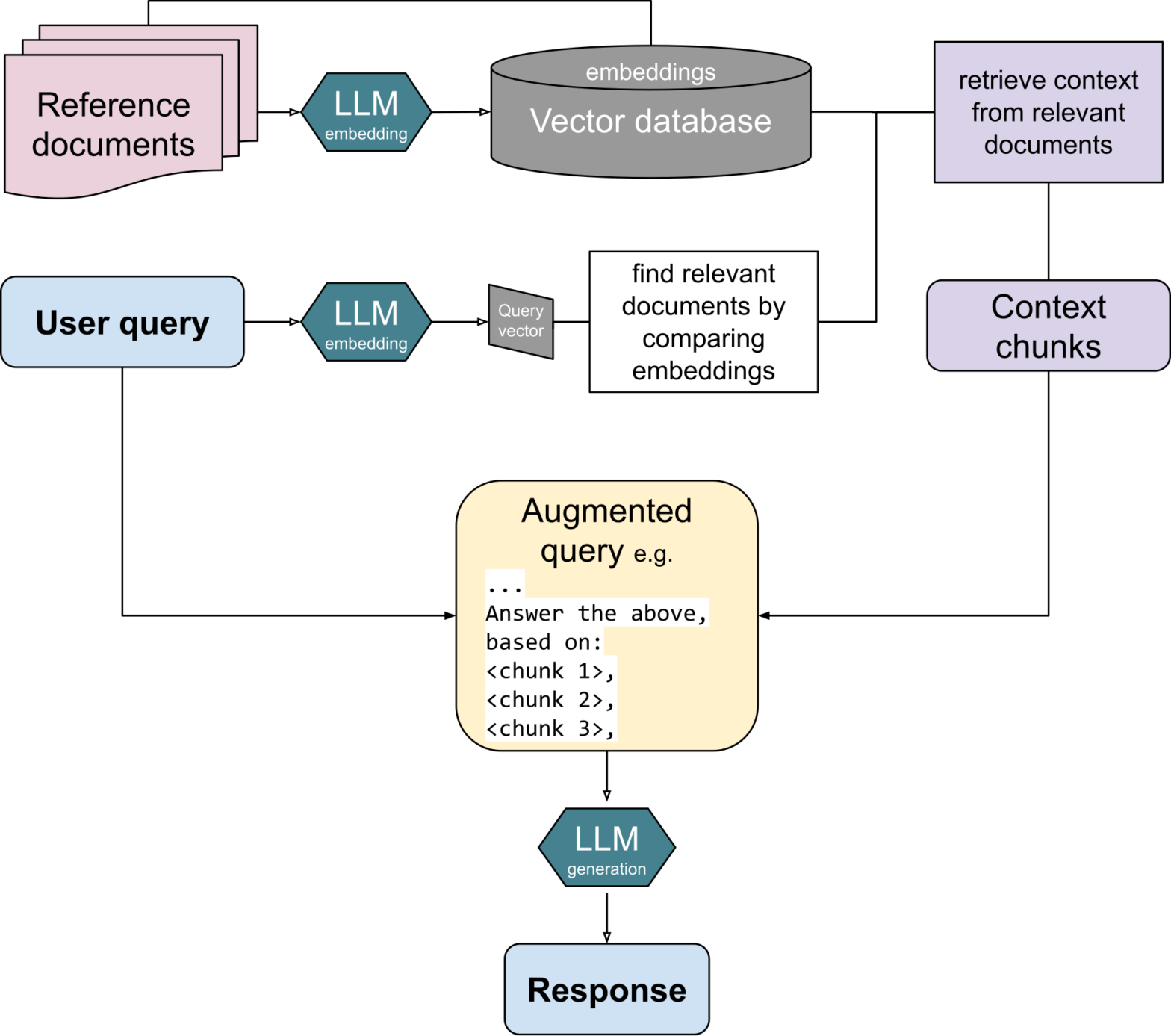
The day has come that you have been waiting for since the ChatGPT hype began: You can now build creative AI apps using your own data in MariaDB Server! By creating embeddings of your own data and storing them in your own MariaDB Server, you can develop RAG solutions where LLMs can efficiently execute prompts based on your own specific data as context.
Why RAG?
Retrieval-Augmented Generation (RAG) creates more accurate, fact-based GenAI answers based on data of your own choice, such as your own manuals, articles or other text corpses. RAG answers are more accurate and fact-based than general Large Language Models (LLM) without having to train or fine-tune a model.
…
Continue reading “Try RAG with MariaDB Vector on your own MariaDB data!”

Today, we are excited to announce a new fund to help give MariaDB Vector a high-quality integration into as many LLM frameworks as possible. This means that you can get rewarded for integrating MariaDB Vector into a known framework! This program will run until the end of February 2025.
How it will work
- Pick a framework: You need to pick one of the frameworks from the list curated by Qdrant that you would like to work on adding MariaDB Vector support to.
- Contact us: Contact us on the MariaDB Zulip, in the General channel, just create a topic.
…
Continue reading “Announcing the MariaDB Vector Bounty Program!”

{kind=link}
We’re here, we’re open source, and we have RDBMS based Vector Search for you! With the release of MariaDB 11.6 Vector Preview, the MariaDB Server ecosystem can finally check out how the long-awaited Vector Search functionality of MariaDB Server works. The effort is a result of collaborative work by employees of MariaDB plc, MariaDB Foundation and contributors, particularly from Amazon AWS.
Previously on “MariaDB Vector”
If you’re new to Vector, this is what’s happened so far:
- We blogged a number of times about our view of where Gen AI belongs in MariaDB Server
- We showed a first demo in February at our FOSDEM Fringe Event
- We launched a project page on mariadb.org/projects/mariadb-vector/, containing a number of videos
- We went on stage at Intel Vision in London, with AI everywhere
- We blogged about Amazon’s take on Vectors and MariaDB, in “MariaDB is soon a vector database, too“
The main point: MariaDB Vector is ready for experimentation
…