
How To Tune MariaDB Write Performance
This article describes how I tuned MariaDB to give the best write throughput with SSD based storage.
When you have a write-heavy application writing into InnoDB, you will probably experience the InnoDB Checkpoint Blues. The effect manifests as stalls – short periods of time where the troughput falls to zero and I/O activity goes crazy. The phenomenon is well known and described i.e. here. More background about checkpointing can be found here.
The XtraDB fork of the InnoDB engine (and heart of Percona Server) contains some patches with the goal to overcome this odd behavior. MariaDB uses XtraDB as default InnoDB implementation, so we can configure some extra variables and hopefully avoid the checkpoint blues.
The first and most important setting is innodb_io_capacity. This is the approximate number of write operations that your hardware can do. If you don’t know that number, then you can easily find it out. Wait until you experience a stall and run iostat -x. You should see fairly high numbers for wrqm/s and w/s on the device holding your InnoDB table spaces. W/s is the number of write requests that hit the device, wrqm/s is the number of requests that could be merged. The sum of both is what InnoDB was effectively using.
In my case the disk is a RAID-0 of 3 SAS SSDs and I have seen up to 25.000 writes per second. So I set innodb_io_capacity=20000 and leave everything else at the default:
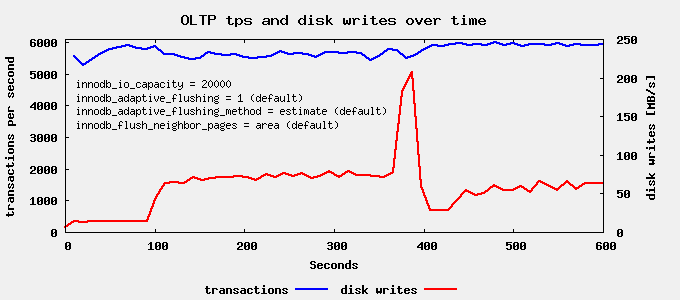
Here we can already see that the stall is gone. However after ~370 seconds we see a rather heavy I/O spike. This is, when XtraDB starts eager flushing when the checkpoint age reaches 75% of the log group capacity.
Now lets see if we can do better. The Percona Server documentation claims: innodb_adaptive_flushing_method=keep_average: … is designed for use with SSD cards. So lets try that next:
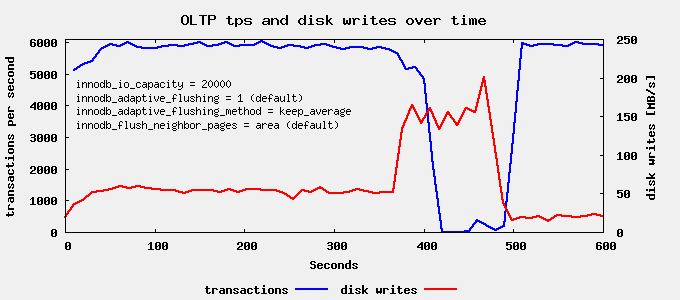
FAIL! Lets quickly revert that to the default.
Next thing to look at, is neighbor page flushing. This works like so: InnoDB pages are organized in blocks of 64 pages. When the checkpointing algorithm has picked a dirty page to be written to disk, it checks if there are more dirty pages in the block and if yes, writes all those pages at once. The rationale is, that with rotating disks the most expensive part of a write operation is head movement. Once the head is over the right track, it does not make much difference if we write 10 or 100 sectors.
The default setting is innodb_flush_neighbor_pages=area. For SSD there is however no head movement penalty. So it makes sense to experiment with the other settings. Lets try innodb_flush_neighbor_pages = cont next:
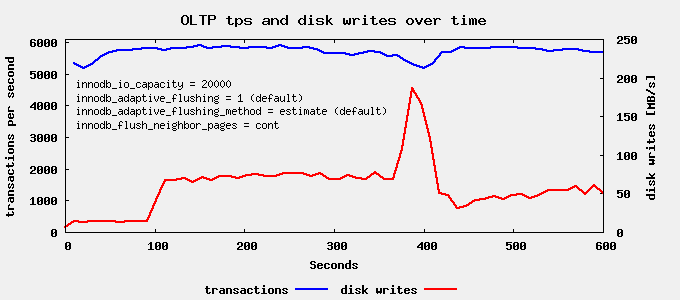
We still see a write spike around 400s run time, but it’s less pronounced than last time. Now lets finally try innodb_flush_neighbor_pages=none
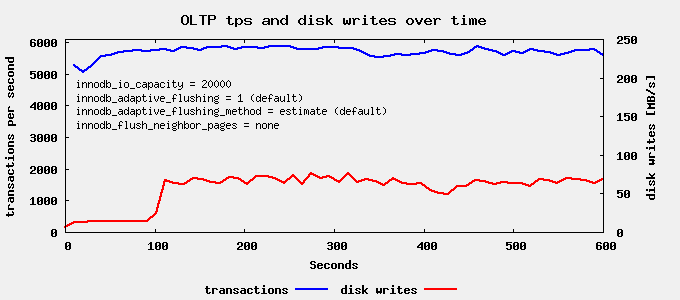
And here we are! For SSD based storage the best parameter combination seems to be: innodb_flush_neighbor_pages = none, innodb_io_capacity = what_your_hardware_can_do and all others at the defaults.
If the storage uses rotating disks, we are probably better off with innodb_flush_neighbor_pages = cont or even innodb_flush_neighbor_pages = area, but at the moment I don’t have the hardware to test that.
Disclaimer: the above graphs use the sysbench OLTP multi table read/write benchmark. Data set size was 10G, InnoDB buffer pool 16G, InnoDB total log capacity 4G.
I think if you would add a graph with also default value for innodb_io_capacity (200) it would give even better image on how important is this setting.