Category Archives: Development

During the last MariaDB Foundation Board Meeting (24 June 2026), Barry shared how it can be difficult to deploy an upgrade immediately and that they sometimes have to wait for one that fixes security bugs. Wait for the validation, wait for the fix, and the release. Even if the MariaDB engineers are doing incredible work, it might still not be fast enough for the security team.
That’s where Barry requested MariaDB implement a query-rewriter plugin, like the one in MySQL, to address the fact that, in a multi-tenant environment, certain queries that would trigger known vulnerabilities are never legitimately used by applications.
…
Continue reading “MariaDB Server Plugins: disabled functions”
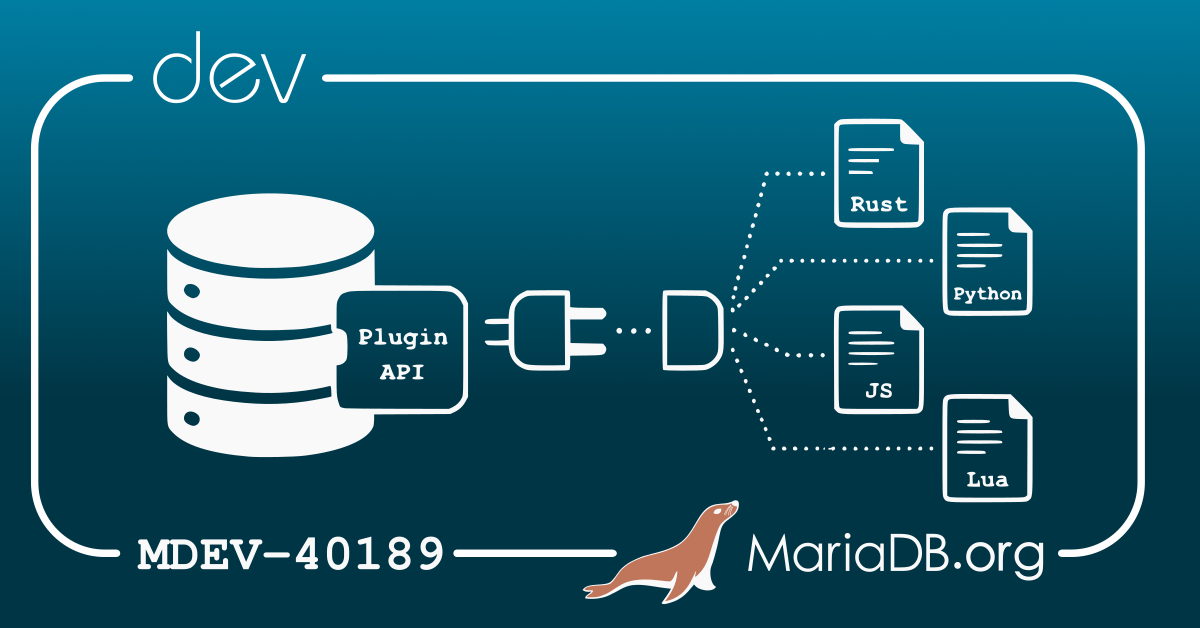
MariaDB Server has long supported a flexible plugin architecture. Plugins allow developers to extend server functionality in areas such as data types, auditing, storage engines, information schema tables, and more.
Today, MariaDB Server plugins are typically developed in C or C++, like the server’s codebase. At least for a while
Even with the current plugin-writing approach, familiarity with MariaDB internals is beneficial because it enables you to do things you otherwise cannot. But it is not required.
A new development idea, MDEV-40189: Support plugins written in various languages, explores whether MariaDB Server could make plugin development accessible from additional programming languages.
…
Continue reading “Lowering the Barrier for MariaDB Plugin Development: Plugins in More Languages”

laravel-mariadb-vector is an open-source project by Erik Ros, bringing MariaDB’s native vector search to Laravel’s Eloquent ORM. In his guest post, Erik shares how it works, and his insights about picking an embedding model.
I maintain laravel-mariadb-vector, a small open source package that brings MariaDB’s native vector search to Laravel’s Eloquent ORM. It’s my first open source project, it has over 100 installs, no marketing budget, and it exists because I needed it.
This post is a quick introduction and an experiment with 2,942 job titles in English and Dutch that shows why the embedding model you pick and how you use it matters far more than you might expect.
…
Continue reading “MariaDB Vector in Laravel: insights on choosing an embedding model”
Have you ever written a query where the GROUP BY was easy, but the aggregate was the problem?
You know how to group the rows.
You know what result you want for each group.
But none of the built-in aggregate functions really match your logic.
So you end up with a long expression using SUM(), CASE, IF(), GROUP_CONCAT(), JSON functions, or application-side code. It works, but it is not beautiful. And if you need the same logic in several places, it becomes even worse.
This is exactly the kind of problem MariaDB’s CREATE AGGREGATE FUNCTION solves.
…
Continue reading “MariaDB Hidden Gem: Create Aggregate Function”
Who says developing MariaDB plugins is hard? I was able to produce one in under 3 minutes!
I of course did it by asking Grok nicely:
The produced result is actually very decent:
/*
errorwatch.c – MariaDB Audit API plugin
Records statement execution errors into a dedicated log file.
This plugin subscribes to the GENERAL audit class and logs
events of type MYSQL_AUDIT_GENERAL_ERROR (and STATUS events
that carry a non-zero error code). It writes structured
entries to /var/log/mariadb/errorwatch.log (or /tmp/ fallback).
To build (inside MariaDB source tree):
1. Copy this file and CMakeLists.txt to plugin/errorwatch/
2. …
Continue reading “Vibe-coding an Audit Plugin in Under 3 Minutes”
If you ever considered contributing code to the MariaDB server, you should know that this is an intricate process involving multiple steps and multiple actors. To help you see your contributions successfully merged into the MariaDB Server codebase I’ve compiled a comprehensive description of the contribution process itself, the roles involved into it, the sequence of actions and conditions for transition from one to another. There’s even a diagram!
Please go to COMMUNITY_CONTRIBUTIONS.md.
This of course is going to be a moving target! I fully intend to keep the document up to date and enhance it with clarifications and process changes as they happen.
…
Continue reading “Documented: The MariaDB Server (Community) Contribution Process”

One of the corner stones in MariaDB Foundation’s mission is:
We strive to increase adoption by users and across use cases, platforms and means of deployment.
MariaDB Server plugins are definitely a prime “means of deployment” for server features. But a relatively neglected one so far. They have been around for many years. But, somehow, they have escaped the user’s focus. Why that happened is a very interesting topic. And one that I’d definitely like to hear your opinion on!
Which brings me to my main topic: How do we all change that?
…

{kind=link}
{kind=link}
We are concluding our series related to new data types using the Type_handler framework, with some limitations that are not yet covered by the framework:
- No custom indexing methods. A plugin type cannot introduce a new indexing method.
- No custom hashing. Plugin types can’t provide their own function for hash-based operations. Things like MEMORY table indexes, GROUP BY, and partitioning fall back to the underlying type’s hash.
- No new field attributes. Plugin types cannot define custom attributes beyond the existing ones: length, precision, scale, and GIS SRID.
…
Continue reading “Adding a New Data Type to MariaDB with Type_handler – Part 5”