Category Archives: Contributions
When we talk about open source contributions, we often focus immediately on the code.
How many lines were changed?
What feature was added?
What do the benchmarks show?
But sometimes, the most interesting part is not the feature itself. It is the journey that transforms a production problem inside one company into an improvement available to an entire community.
This is exactly what happened with Headout, Arcadiy Ivanov (Karellen, Inc), and MariaDB Server.
The technical result is support for BLOB values in in-memory internal temporary tables.
…
Continue reading “From a Production Problem to MariaDB: Headout’s Open-Source Contribution Journey”
Some contributions improve MariaDB Server by adding new capabilities.
Some go further: they start from a concrete production problem with an existing feature, not a bug, but a design limitation, solve it upstream, and leave the whole ecosystem better off.
This is one of those contributions.
The platform team at Headout, a global platform that helps travelers discover and book curated real-life experiences, encountered a few inefficiencies in MariaDB Server around temporary tables and the HEAP engine. Instead of treating these as isolated local problems, they worked upstream. Arcadiy Ivanov, operating through Karellen, Inc.
…

MariaDB 13.1 Preview is full of nice things.
Some are immediately visible to developers, like the new JSON operators. Some are very useful to DBAs, such as configuration validation. And some are about making security and access control easier to manage.
Today, let’s look at one of those: DENY, also known as negative grants.
Yes, negative grants.
It sounds a bit strange the first time you hear it, but the idea is very simple:
Sometimes it is easier to say “you can access everything here, except this”.
…
Continue reading “MariaDB 13.1 Feature in Focus: DENY / Negative Grants”

We just announced the availability of a preview of the MariaDB 13.1 series.
MariaDB 13.1 is a rolling release preview, and, as usual, this is the right moment to test what is coming, give feedback, and help us polish the next MariaDB Server release.
But this time, there is something really interesting.
And by “interesting”, I mean: wow!
MariaDB 13.1 Preview includes 32 MDEVs with new features and improvements. To put that in perspective:
| MariaDB Server 12.2 | 11 |
| MariaDB Server 12.3 | 15 |
| MariaDB Server 13.0 | 17 |
| MariaDB Server 13.1 | 32 |
How to make Joro happy
That is almost twice MariaDB 13.0, more than twice MariaDB 12.3, and almost three times MariaDB 12.2.
…
Continue reading “MariaDB 13.1 Preview: This One Is Full of Community Goodies!”
Tracking down changes in database performance is one of the hardest parts of engineering, especially when the change is buried somewhere in a long commit history.
To make this work easier and more repeatable, I put together a small but important tool:
This script does one thing well:
Given a commit hash, it checks out that commit, builds it cleanly, and packages it in a deterministic way so the Test Automation Framework (TAF) can run consistent performance tests.
Why this matters
- When you are bisecting or doing a manual binary search across hundreds of commits, you need reproducible builds.
…
Continue reading “Simple tool to build MariaDB commits for performance-change analysis”

On May… we have released an update of our 5 current LTS releases:
These new releases contain a large amount of external contributions. The number of contributors is constantly growing, which is great!
On behalf of the MariaDB Foundation and the entire MariaDB Team, let me thank you all!
If we refer to MariaDB Server 11.8, we have about 62 contributions from 35 external contributors.
…

An early look at the DuckDB storage engine for MariaDB — columnar, vectorized analytics that live right next to your transactional tables.
The problem
MariaDB’s InnoDB is excellent at what it was built for: transactions. Row-by-row inserts, updates, point lookups, strong consistency. But the moment you ask it to scan tens of millions of rows for a multi-way join with a few aggregations, a row store has to work hard.
The usual answer is to stand up a separate analytical system, then build ETL pipelines to copy data into it.
…
Continue reading “DuckDB Storage Engine for MariaDB. When the Sea Lion Learns to Quack.”
{kind=link}
{kind=link}
{kind=link}
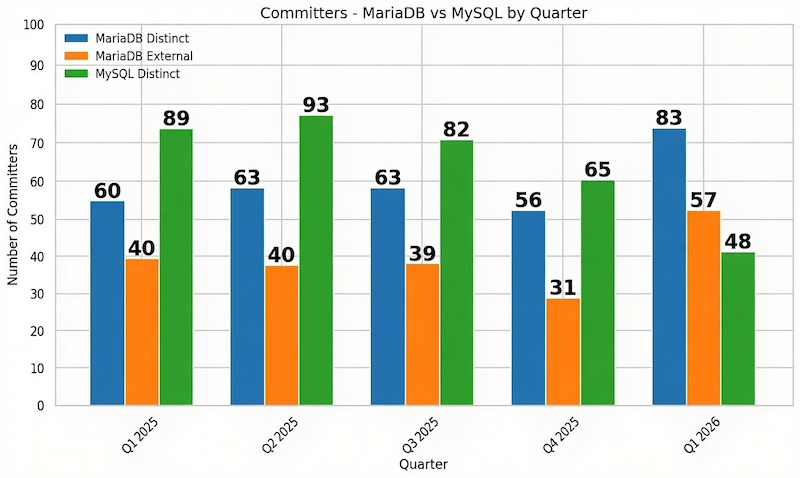
Inspired by some recent LinkedIn posts, I decided to take the AI in my own hands and do some stats on the MariaDB and MySQL repositories.
This graph is what I’ve got.
Not only have MariaDB Server distinct contributors surpassed the distinct MySQL Server contributors count! The External MariaDB contributors alone did! *
This is how the Power Of the Community looks like!
- You get to use a more functional, performant and error free MariaDB Server
- You get a say in shaping the future of the MariaDB Server.
…