Category Archives: Generic

Names are important.
They help us identify people, projects, products, pets, database servers, and occasionally the correct bug tracker.
This may sound obvious, but the database world has spent more than fifteen years proving that it is not.
MySQL and MariaDB share a substantial amount of history, syntax, tooling, knowledge, applications, and community. They also have similar command names, compatible protocols, familiar configuration variables, and many users who simply say “MySQL” when they actually mean:
Some database server that speaks the MySQL protocol and probably has an executable named mysqld.
And most of the time, everybody understands.
…
Continue reading “Say the Name: MariaDB, MySQL, and the Ecosystem We Share”
Have you ever modified a MariaDB configuration file, restarted the service, and immediately regretted it?
You wanted to change:
innodb_buffer_pool_size=16G
but accidentally wrote:
innodb_buffer_pool_sze=16G
One missing letter.
That is enough to turn a perfectly healthy database server into a service that refuses to start.
And of course, this kind of mistake never happens during a quiet maintenance window when everybody is available.
It happens during an automated deployment.
It happens during an upgrade.
It happens on a remote server.
Or it happens just before you planned to leave for dinner.
…
TAF 3.0 introduces the new TAF Results Backend, a structured results database and parser pipeline that delivers fully automated performance change detection. This system uses a deterministic workload hash, schema‑driven baselines, and stored‑procedure‑driven comparison. No procedural comparison code. No special‑case logic. Everything is clean and automatic.
Workload Hash
Every test run gets a workload hash and parser builds it from:
- test + suite identity
- system identity
- database maker + engine
- database version normalized to major only (MariaDB, MySQL, PG, any maker)
- configuration identity
- workload parameters (threads, rows, tables, ranges, warmup, connector)
- harness + client versions
- iteration count
- requested duration
This hash is the identity of the workload.
…
Continue reading “TAF 3.0 — Results Backend With Automated Performance Change Detection”
We are pleased to announce the availability of a preview of the MariaDB 13.1 series. MariaDB 13.1 will be a rolling release.
MariaDB 13.1 introduces a lot of new features. Many of them were implemented by our awesome community contributors. See the complete list below:
- DENY clause for access control a.k.a. “negative grants” (MDEV-14443)
- Auto-adding new partitions for PARTITION BY RANGE (MDEV-15621)
- Locking full table scan fails to use table-level locking (MDEV-24813)
- The default utf8 character set is now utf8mb4 (MDEV-30041)
- NEW and OLD in a trigger can be used as row variables (MDEV-34723)
- ADAPTIVE_HASH_INDEX = { YES | NO | DEFAULT } can specify per InnoDB table whether to use AHI (MDEV-37070)
- XMLISVALID() schema validation function (MDEV-37262)
- Adaptive hash index statistics is shown in ANALYZE FORMAT=JSON (MDEV-38305)
- Optimizer Context Recorder to record the optimizer data and then analyze query optimization on another server instance (MDEV-38701)
- innodb_tablespace_size_warning_threshold and innodb_tablespace_size_warning_pct variables to get a warning when InnoDB tablespace is getting close to full (before it’s 100% full and the service is disrupted) (MDEV-38936)
- Local routine variables usable in PREPARE/EXECUTE/DEALLOCATE and OPEN …
…

laravel-mariadb-vector is an open-source project by Erik Ros, bringing MariaDB’s native vector search to Laravel’s Eloquent ORM. In his guest post, Erik shares how it works, and his insights about picking an embedding model.
I maintain laravel-mariadb-vector, a small open source package that brings MariaDB’s native vector search to Laravel’s Eloquent ORM. It’s my first open source project, it has over 100 installs, no marketing budget, and it exists because I needed it.
This post is a quick introduction and an experiment with 2,942 job titles in English and Dutch that shows why the embedding model you pick and how you use it matters far more than you might expect.
…
Continue reading “MariaDB Vector in Laravel: insights on choosing an embedding model”

MariaDB just announced it has learned to quack: the new DuckDB storage engine has joined the large family of storage engines in MariaDB Server.
The idea is very interesting: use MariaDB Server as usual, but create some tables using ENGINE=DuckDB and benefit from DuckDB’s columnar storage and vectorized execution for analytical queries.
In other words, we can keep our transactional workload in InnoDB, and use DuckDB tables for analytics… in the same MariaDB instance. Not a new concept, but a new and powerful implementation!
This is, of course, not something I would recommend for production today;
…

An early look at the DuckDB storage engine for MariaDB — columnar, vectorized analytics that live right next to your transactional tables.
The problem
MariaDB’s InnoDB is excellent at what it was built for: transactions. Row-by-row inserts, updates, point lookups, strong consistency. But the moment you ask it to scan tens of millions of rows for a multi-way join with a few aggregations, a row store has to work hard.
The usual answer is to stand up a separate analytical system, then build ETL pipelines to copy data into it.
…
Continue reading “DuckDB Storage Engine for MariaDB. When the Sea Lion Learns to Quack.”
{kind=link}
{kind=link}
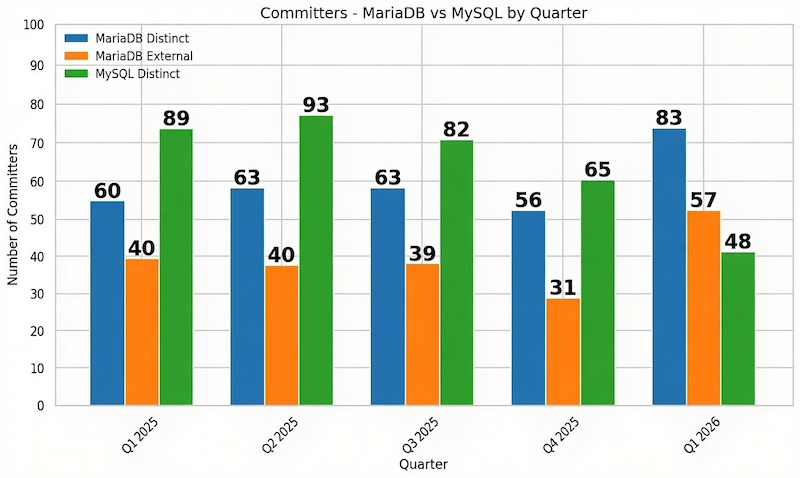
Inspired by some recent LinkedIn posts, I decided to take the AI in my own hands and do some stats on the MariaDB and MySQL repositories.
This graph is what I’ve got.
Not only have MariaDB Server distinct contributors surpassed the distinct MySQL Server contributors count! The External MariaDB contributors alone did! *
This is how the Power Of the Community looks like!
- You get to use a more functional, performant and error free MariaDB Server
- You get a say in shaping the future of the MariaDB Server.
…