Author Archives: Robert Bindar
MariaDB has been using a pluggable storage engine architecture for a long time and whilst this means great flexibility in choosing and managing the right storage engines for specific use cases, it also means they are easier to develop and therefore there’s an expectation that more engines will be created.
More storage engines means the MariaDB Server itself needs to be as flexible as possible to accommodate all sorts of functionalities that storage engines may need. One area where the MariaDB Server proved to be not that welcoming was in making available all the compression libraries needed by storage engines.
…
Continue reading “10.7 preview feature: Compression Provider Plugins”
We are proud to announce the beta release series of the MariaDB Jupyter Kernel, making MariaDB Server accessible through the popular next-generation web-based interface.
The MariaDB Kernel is ready to try out (installation, documentation, GitHub).
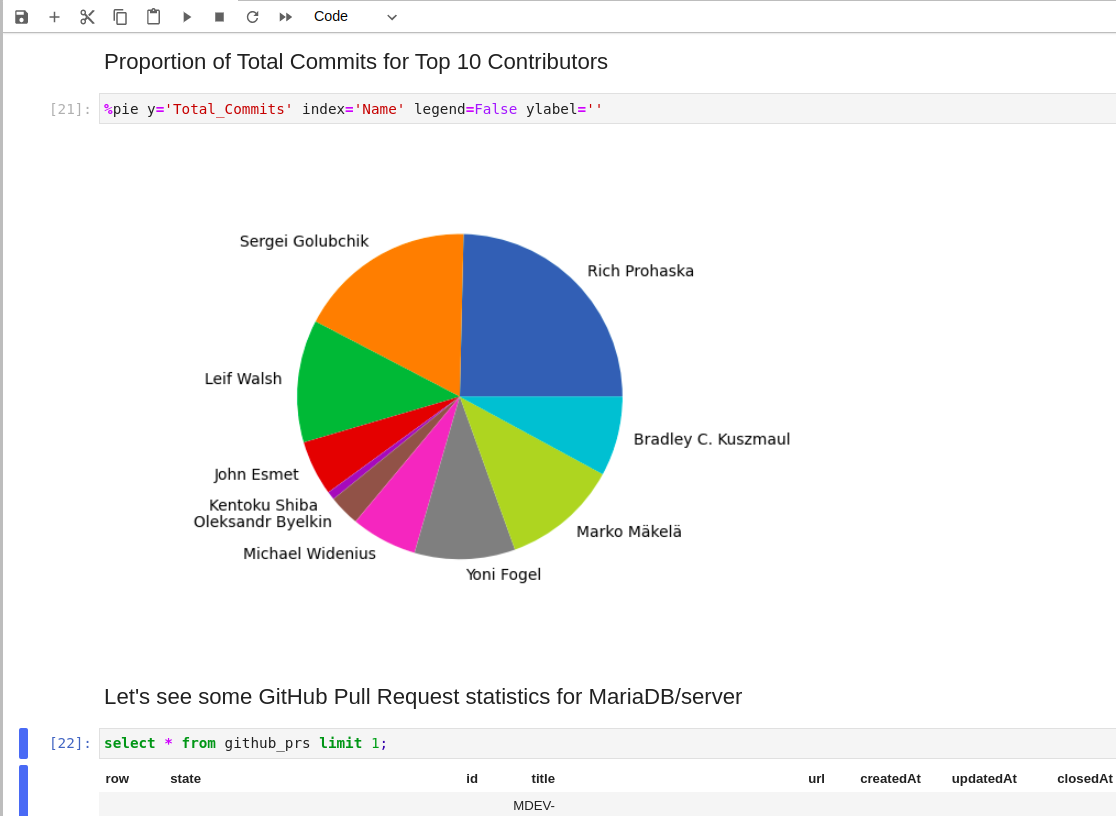{kind=link}
For all who love the easy Jupyter user interface, there is now a way to access the MariaDB Server from everyone’s favorite notebook.
The MariaDB Jupyter Kernel is as simple as it gets. It’s a “normal” MariaDB character based command line client, extended in two ways: First, it has all the standard Jupyter usability functionality for editing and saving MariaDB SELECT, INSERT, UPDATE and DELETE commands.
…
Last Wednesday, I received an unexpected text: “Would you like to do some volunteering work? It involves speaking online to some kids for one hour about IT”. It was a classmate from high school.
MariaDB Foundation employees work remotely. Sure, we all meet together in one place a number of times a year so we don’t forget each other’s faces, but in 99% of our logged time, we are distributed around the globe. We are also not required to have a strict working schedule and this offers us the opportunity to say yes easily to these sort of events.
…