Tag Archives: MariaDB

Names are important.
They help us identify people, projects, products, pets, database servers, and occasionally the correct bug tracker.
This may sound obvious, but the database world has spent more than fifteen years proving that it is not.
MySQL and MariaDB share a substantial amount of history, syntax, tooling, knowledge, applications, and community. They also have similar command names, compatible protocols, familiar configuration variables, and many users who simply say “MySQL” when they actually mean:
Some database server that speaks the MySQL protocol and probably has an executable named mysqld.
And most of the time, everybody understands.
…
Continue reading “Say the Name: MariaDB, MySQL, and the Ecosystem We Share”

MariaDB Foundation is pleased to welcome Continuent as a new Silver Sponsor.
Continuent develops solutions for organizations running business-critical applications on MariaDB and other MySQL-compatible databases. Its flagship product, Tungsten Cluster, helps organizations manage database availability, disaster recovery and distributed deployments across on-premises, cloud and hybrid environments.
The company has worked with open-source database technologies for more than two decades and brings extensive experience from demanding production environments across SaaS, financial services, telecommunications, e-commerce and other industries.
“Continuent has a long history in the MariaDB and wider open-source database ecosystem.
…
Continue reading “Continuent joins MariaDB Foundation as a Silver Sponsor”

MariaDB Foundation is pleased to announce that Nextcloud has renewed its Silver sponsorship for another year.
Nextcloud and MariaDB are widely used together by organisations that want greater control over their data and infrastructure. Both projects form part of a broader open-source ecosystem that enables businesses, public-sector organisations and individuals to build digital services without unnecessary dependence on proprietary platforms.
Over the past year, our collaboration has also developed through the Privacy-First Solution Stack, which brings together Nextcloud, Passbolt and MariaDB Server in a practical open-source architecture for secure collaboration, password management and data storage.
…
Continue reading “Nextcloud renews its Silver sponsorship of MariaDB Foundation”

MariaDB Foundation is pleased to announce that Passbolt has renewed its Silver sponsorship for another year, continuing its long-term support for the MariaDB open-source ecosystem.
Passbolt is an open-source password manager designed for teams, with a strong focus on security, privacy, and user control. Its continued support reflects a shared commitment to building practical, trustworthy open-source infrastructure that organizations can deploy and operate with confidence.
Building on the Privacy-First Stack
During the first year of collaboration, Passbolt became part of the Privacy-First Solution Stack alongside Nextcloud and MariaDB Server.
…
Continue reading “Passbolt renews its support for MariaDB Foundation”
Tracking down changes in database performance is one of the hardest parts of engineering, especially when the change is buried somewhere in a long commit history.
To make this work easier and more repeatable, I put together a small but important tool:
This script does one thing well:
Given a commit hash, it checks out that commit, builds it cleanly, and packages it in a deterministic way so the Test Automation Framework (TAF) can run consistent performance tests.
Why this matters
- When you are bisecting or doing a manual binary search across hundreds of commits, you need reproducible builds.
…
Continue reading “Simple tool to build MariaDB commits for performance-change analysis”

An early look at the DuckDB storage engine for MariaDB — columnar, vectorized analytics that live right next to your transactional tables.
The problem
MariaDB’s InnoDB is excellent at what it was built for: transactions. Row-by-row inserts, updates, point lookups, strong consistency. But the moment you ask it to scan tens of millions of rows for a multi-way join with a few aggregations, a row store has to work hard.
The usual answer is to stand up a separate analytical system, then build ETL pipelines to copy data into it.
…
Continue reading “DuckDB Storage Engine for MariaDB. When the Sea Lion Learns to Quack.”
{kind=link}
{kind=link}
{kind=link}
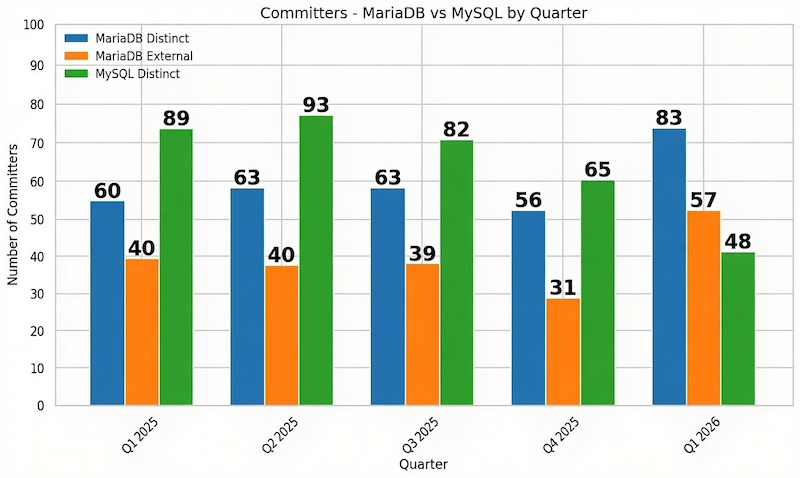
Inspired by some recent LinkedIn posts, I decided to take the AI in my own hands and do some stats on the MariaDB and MySQL repositories.
This graph is what I’ve got.
Not only have MariaDB Server distinct contributors surpassed the distinct MySQL Server contributors count! The External MariaDB contributors alone did! *
This is how the Power Of the Community looks like!
- You get to use a more functional, performant and error free MariaDB Server
- You get a say in shaping the future of the MariaDB Server.
…
…
Continue reading “MariaDB Foundation: Bringing TPC-B Back To Life”