Author Archives: Anel Husakovic

In this blog we will explore how to setup a docker compose file in order to migrate from MySQL 5.7 to the latest MariaDB.
In the next blog we will explain how to setup a docker compose file to migrate from MySQL 8.0 to MariaDB.
The steps to migrate from MySQL 5.7 to MariaDB are:
- Start container by running docker-compose file
- Use the MySQL data directory and start MariaDB with MARIADB_AUTO_UPGRADE=1
Let’s explore each step.
1. Start MySQL
The MySQL container is started using the following docker-compose file.
…

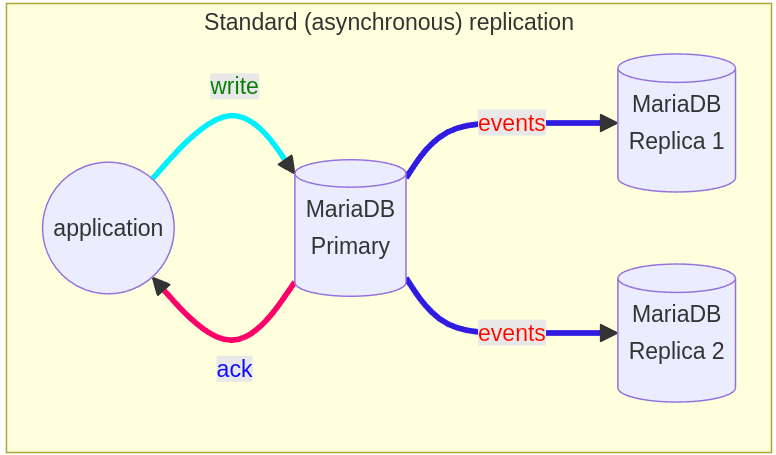
In the blog MariaDB replication using containers, we showed how to properly replicate data in MariaDB using Docker containers.
We used standard or asynchronous or lazy replication.
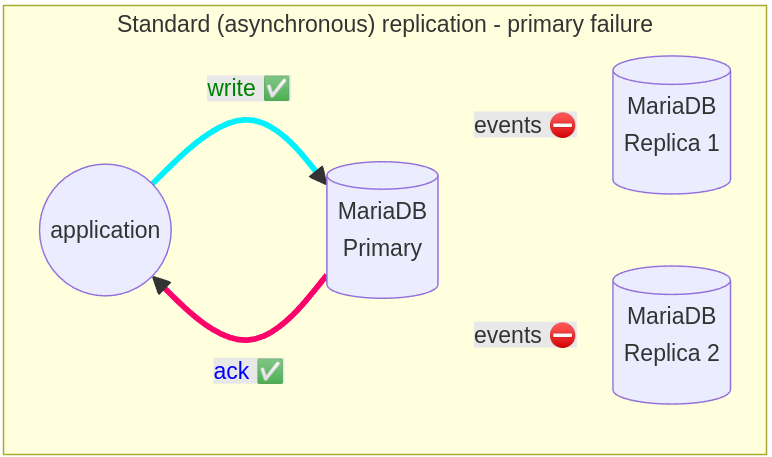
The problem with this type of replication is potential data loss if the primary goes down. Transactions that are committed on the primary are not being sent to replicas, and the replica doesn’t commit the changes. Failover from primary to replica in this case may lead to missing transactions relative to the primary.
To overcome these type of errors, there is semi-sync replication that is integrated into MariaDB since 10.4 and fully sync replication, which we plan to implement eventually as MDEV-19140.
…
Continue reading “MariaDB semi-sync replication using containers”

In this blog we will show how to access MySQL and MariaDB DBMS tables from MariaDB Server. For that we will use Connect Storage Engine (SE), which supports different table types options. In this case we will use the JDBC table type. To use the JDBC table type we need to specify it in the CREATE TABLE definition for Connect SE and we need the Java connector for the DBMS we are accessing. For demonstration purposes we will use containers, but this will work if the servers are running in VMs or bare-metal. Just make sure the machines can access each other via TCP/IP.
…
Continue reading “Connect SE JDBC table type: Accessing Tables From Another DBMS”

{kind=link}
{kind=link}
In this blog we are going to learn how to migrate data from Oracle to MariaDB.
To begin, we’ll learn the basics about Oracle database to have an understanding about the steps that are done on the demo example. After, we will create a table in Oracle and migrate it to MariaDB.
To migrate data from Oracle there are 2 ways:
- Dump Oracle data to CSV and load data in MariaDB.
- Use the Connect Storage Engine to create or insert into a table from Oracle’s source definition.
For demonstration, we are going to use a docker container with an Oracle Express Edition (XE) image.
…
As mentioned in the previous batch of release notes (e.g. 10.6.11), our Yum/DNF/Zypper repositories for Red Hat Enterprise Linux, Centos, Fedora, openSUSE and SUSE will, from our next set of releases, be migrated to being signed with a new GPG key with SHA2 digest algorithms instead of SHA1.
The key we are migrating to is the same one we already use for our Debian and Ubuntu repositories.
- The short Key ID is: 0xC74CD1D8
- The long Key ID is: 0xF1656F24C74CD1D8
- The full fingerprint of the key is: 177F 4010 FE56 CA33 3630 0305 F165 6F24 C74C D1D8
The key can be imported now in preparation for this change using the following command:
sudo rpm –import https://rpm.mariadb.org/RPM-GPG-KEY-MariaDB
Those with a gpgkey=https://mirror/yum/RPM-GPG-KEY-MariaDB in their repo file will still work, you’ll just need to accept the new key on DNF update.
…
Gcov is a coverage testing tool, used to create better programs. It can show which parts of the codebase are untested. Gcov is located in the same package as gcc. MariaDB takes care of code quality and checks test coverage with Gcov. We are looking forward to have Gcov used soon as a part of our buildbot (MDBF-158).
How to use Gcov
Let’s write a demo example to demonstrate how it works.
— Source code:
$ cat -n test.c
int f1()
{
return 0; …
MariaDB 10.11.0, our latest preview release, features quite a number of improvements. The one we’ll talk about here is replicate-rewrite-db. This option has become a system variable from 10.11.0 based on MDEV-15530. Before this version it was just an option used by the mariadbd and mariadb-binlog binaries. There have been no behaviour changes with the option; it has simply become a dynamic variable.
How to try out this feature
The fastest way is to take MariaDB 10.11 for a spin in docker / podman (consult the blog mariadb-replication-using-containers) with the following commands:
To start a primary 10.11.0 MariaDB container, clone the directory, navigate to the cloned directory and run the following command:
docker run -d –rm –name mariadb-primary \
-v $PWD/config-files/primarycnf:/etc/mysql/conf.d:z \
-v $PWD/primaryinit:/docker-entrypoint-initdb.d:z \
-v $PWD/log-files-primary:/var/lib/mysql \
-e MARIADB_ALLOW_EMPTY_ROOT_PASSWORD=True \
quay.io/mariadb-foundation/mariadb-devel:10.11
To start the replica/secondary run the command to start the mariadbd process as well as specify the replicate-rewrite-db option on the command line:
docker run -d –rm –name mariadb-secondary-1 \
-v $PWD/config-files/secondary-1:/etc/mysql/conf.d:z \
-v $PWD/secondaryinit:/docker-entrypoint-initdb.d:z \
-v $PWD/log-files-secondary-1:/var/lib/mysql \
-e MARIADB_ALLOW_EMPTY_ROOT_PASSWORD=True \
quay.io/mariadb-foundation/mariadb-devel:10.11 –replicate-rewrite-db=’db1->db2′
Besides specifying the option as a command line argument, you can use a configuration file.
…
Continue reading “replicate_rewrite_db as a system variable in MariaDB”
In the previous blog we have seen how to create a statefulset MariaDB application. Also, we learned how replication works in MariaDB in this blog. Now, we will try to create a replicated statefulset application. As good references for creating this blog, I would like to give credit to the Kubernetes documentation as well as an example from Alibaba Cloud.
Configure replication
To replicate a MariaDB application we are going to create a statefulset that will consist of a single init container and one application container.
…
Continue reading “MariaDB & K8s: How to replicate MariaDB in K8s”