

We are very pleased to welcome ProxySQL as a Silver Sponsor of the MariaDB Foundation.
ProxySQL is the leading proxy for MySQL and has recently focused on supporting more and more of MariaDB, both with the Proxy and with other open-source projects ProxySQL is stewarding, like dbdeployer and orchestrator.
I had the chance to interview René Cannaò, CEO of ProxySQL.
Why is it important for ProxySQL to sponsor an organization like the MariaDB Foundation?
ProxySQL was born within the MySQL ecosystem, and MariaDB has always been an important part of it.
…
Continue reading “ProxySQL joins MariaDB Foundation as Silver Sponsor”
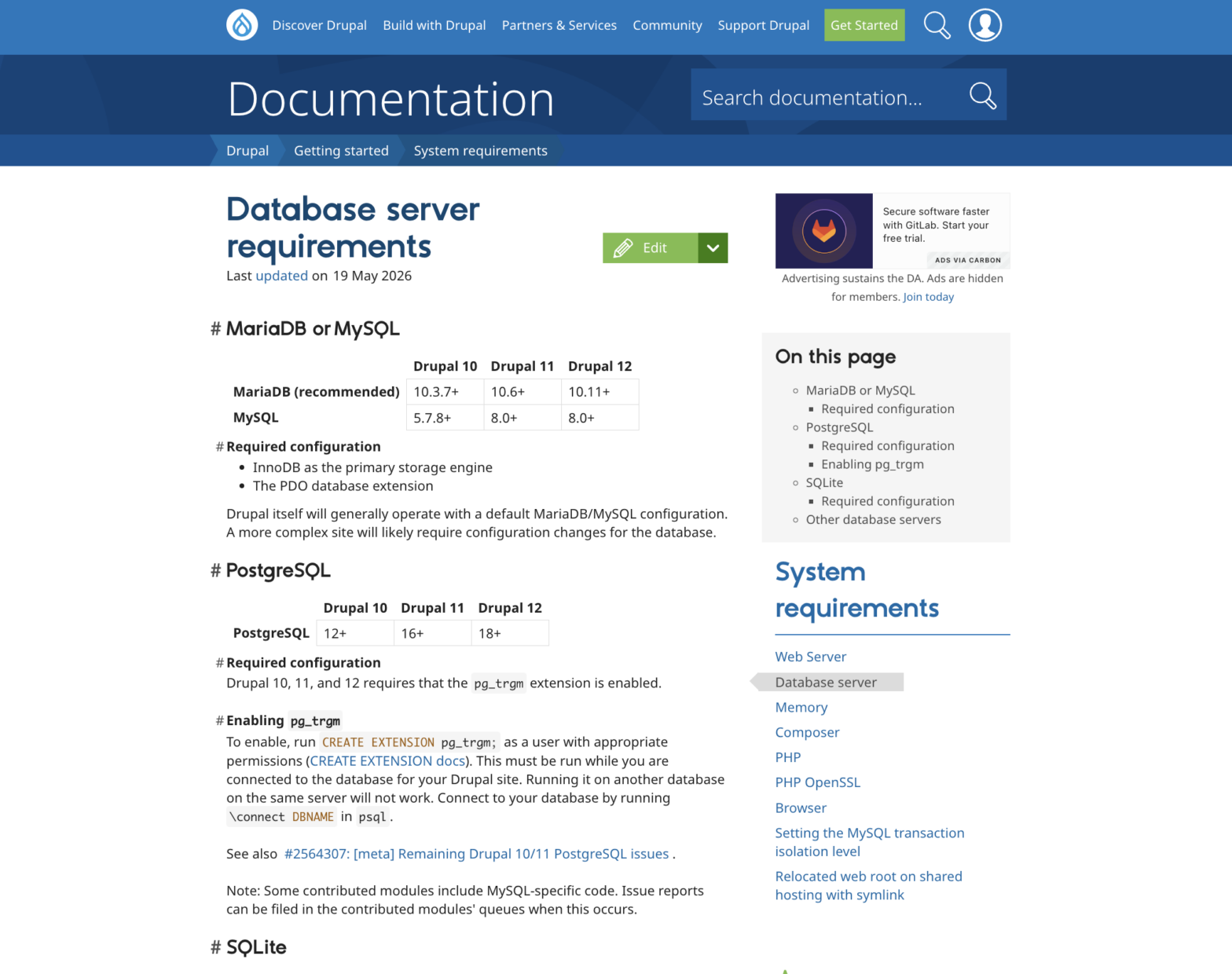
MariaDB is now clearly listed as the recommended database in Drupal’s official documentation. Following community discussion on Drupal.org, the Database server requirements now lists MariaDB first, and identifies it as the recommended database for Drupal 10, 11, and 12. Drupal is a major open source content management system—a flexible platform used by a substantial share of websites globally.
We’re glad to see this. Recognition matters because MariaDB is often used but documented as MySQL, going unnoticed under the hood—and when it goes unnamed, the work behind it loses visibility, a point Anna Widenius made in “I Am Not Building Cadillacs Anymore“, on how Henry Ford was long mistaken for the company that took his designs and became Cadillac.
…
Who says developing MariaDB plugins is hard? I was able to produce one in under 3 minutes!
I of course did it by asking Grok nicely:
The produced result is actually very decent:
/*
errorwatch.c – MariaDB Audit API plugin
Records statement execution errors into a dedicated log file.
This plugin subscribes to the GENERAL audit class and logs
events of type MYSQL_AUDIT_GENERAL_ERROR (and STATUS events
that carry a non-zero error code). It writes structured
entries to /var/log/mariadb/errorwatch.log (or /tmp/ fallback).
To build (inside MariaDB source tree):
1. Copy this file and CMakeLists.txt to plugin/errorwatch/
2. …
Continue reading “Vibe-coding an Audit Plugin in Under 3 Minutes”
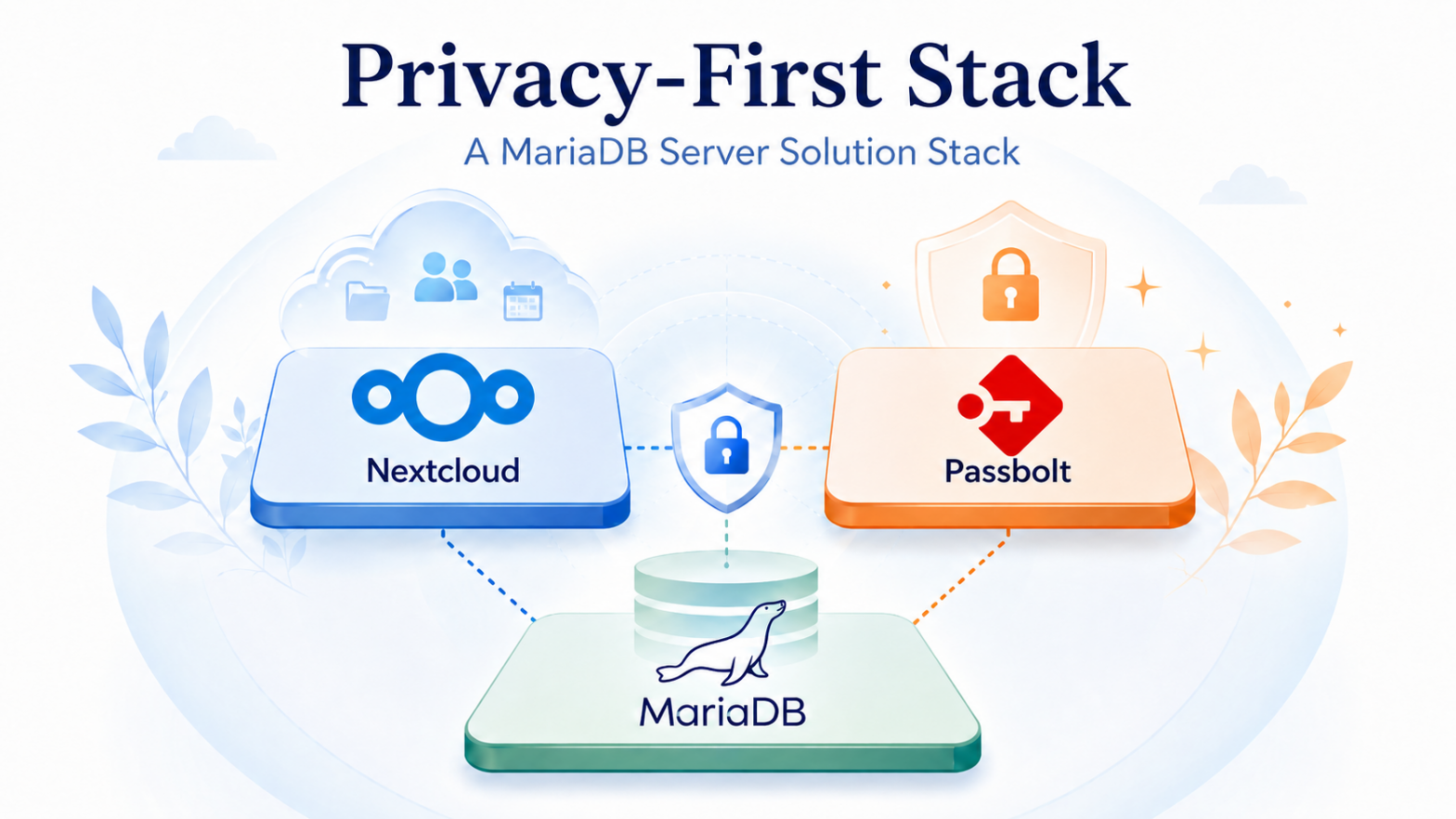
MariaDB Foundation is pleased to announce the publication of our first MariaDB Server Solution Stack in the MariaDB Server Ecosystem Hub:
Privacy-First Stack: Nextcloud, Passbolt, and MariaDB Server
This stack brings together three open-source technologies with a shared purpose: helping organizations build collaboration infrastructure around privacy, control, and long-term digital sovereignty.
The stack combines:
- Nextcloud for file sharing, synchronization, and collaboration
- Passbolt for password, credential, and secrets management
- MariaDB Server as the open-source relational database layer at the core
Together, they form a practical architecture for organizations that want to keep collaboration data, credentials, and structured data under their own control.
…
If you ever considered contributing code to the MariaDB server, you should know that this is an intricate process involving multiple steps and multiple actors. To help you see your contributions successfully merged into the MariaDB Server codebase I’ve compiled a comprehensive description of the contribution process itself, the roles involved into it, the sequence of actions and conditions for transition from one to another. There’s even a diagram!
Please go to COMMUNITY_CONTRIBUTIONS.md.
This of course is going to be a moving target! I fully intend to keep the document up to date and enhance it with clarifications and process changes as they happen.
…
Continue reading “Documented: The MariaDB Server (Community) Contribution Process”

One of the corner stones in MariaDB Foundation’s mission is:
We strive to increase adoption by users and across use cases, platforms and means of deployment.
MariaDB Server plugins are definitely a prime “means of deployment” for server features. But a relatively neglected one so far. They have been around for many years. But, somehow, they have escaped the user’s focus. Why that happened is a very interesting topic. And one that I’d definitely like to hear your opinion on!
Which brings me to my main topic: How do we all change that?
…

We are concluding our series related to new data types using the Type_handler framework, with some limitations that are not yet covered by the framework:
- No custom indexing methods. A plugin type cannot introduce a new indexing method.
- No custom hashing. Plugin types can’t provide their own function for hash-based operations. Things like MEMORY table indexes, GROUP BY, and partitioning fall back to the underlying type’s hash.
- No new field attributes. Plugin types cannot define custom attributes beyond the existing ones: length, precision, scale, and GIS SRID.
…
Continue reading “Adding a New Data Type to MariaDB with Type_handler – Part 5”

{kind=link}
This is part 4 of a series related to extending MariaDB with a custom data type using the Type_handler framework.
You can find the previous articles below:
- Adding a New Data Type to MariaDB with Type_handler – Part 0 – how to build MariaDB Server
- Adding a New Data Type to MariaDB with Type_handler – Part 1 – understanding the framework
- Adding a New Data Type to MariaDB with Type_handler – Part 2 – minimal working data type
- Adding a New Data Type to MariaDB with Type_handler – Part 3 – data type output transformation
Overriding Existing Types
In the previous examples, our MONEY data type inherits from DOUBLE and then we override some methods.
…
Continue reading “Adding a New Data Type to MariaDB with Type_handler – Part 4”