Tag Archives: community
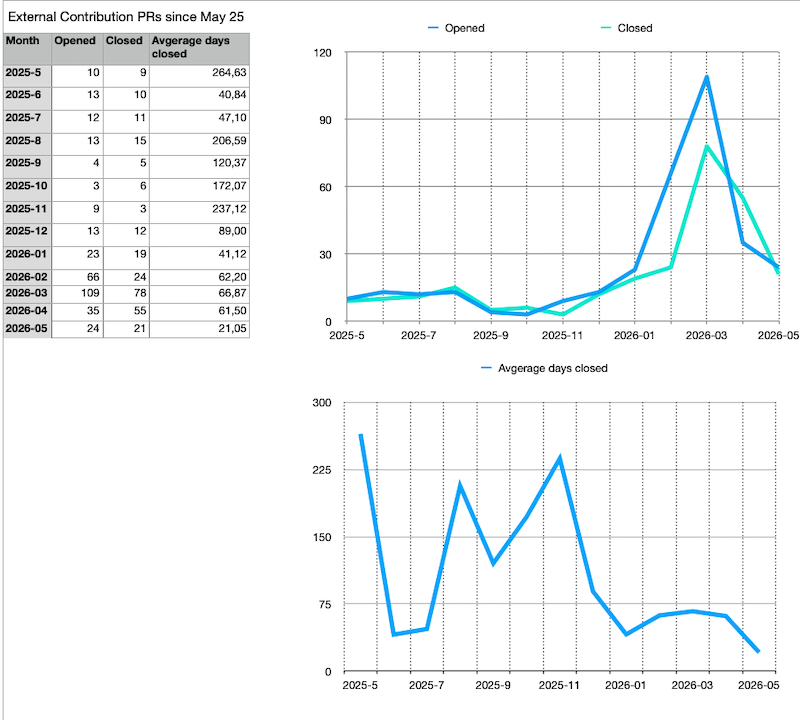
We have a new record average time to process a pull request: 21 days!
Part of my job is following (and trying to improve of course) some key metrics about MariaDB Server pull request processing. As a part of that I compile a nice pull request metric and a graph of it. This is what it looked like for the last month:
There’s a single number that caught my attention: 21.05 ! This is a new record low! That’s how much it takes on average from opening a pull request to closing it for all the requests closed last month!
…
Continue reading “A New Pull Request Processing Time Record”
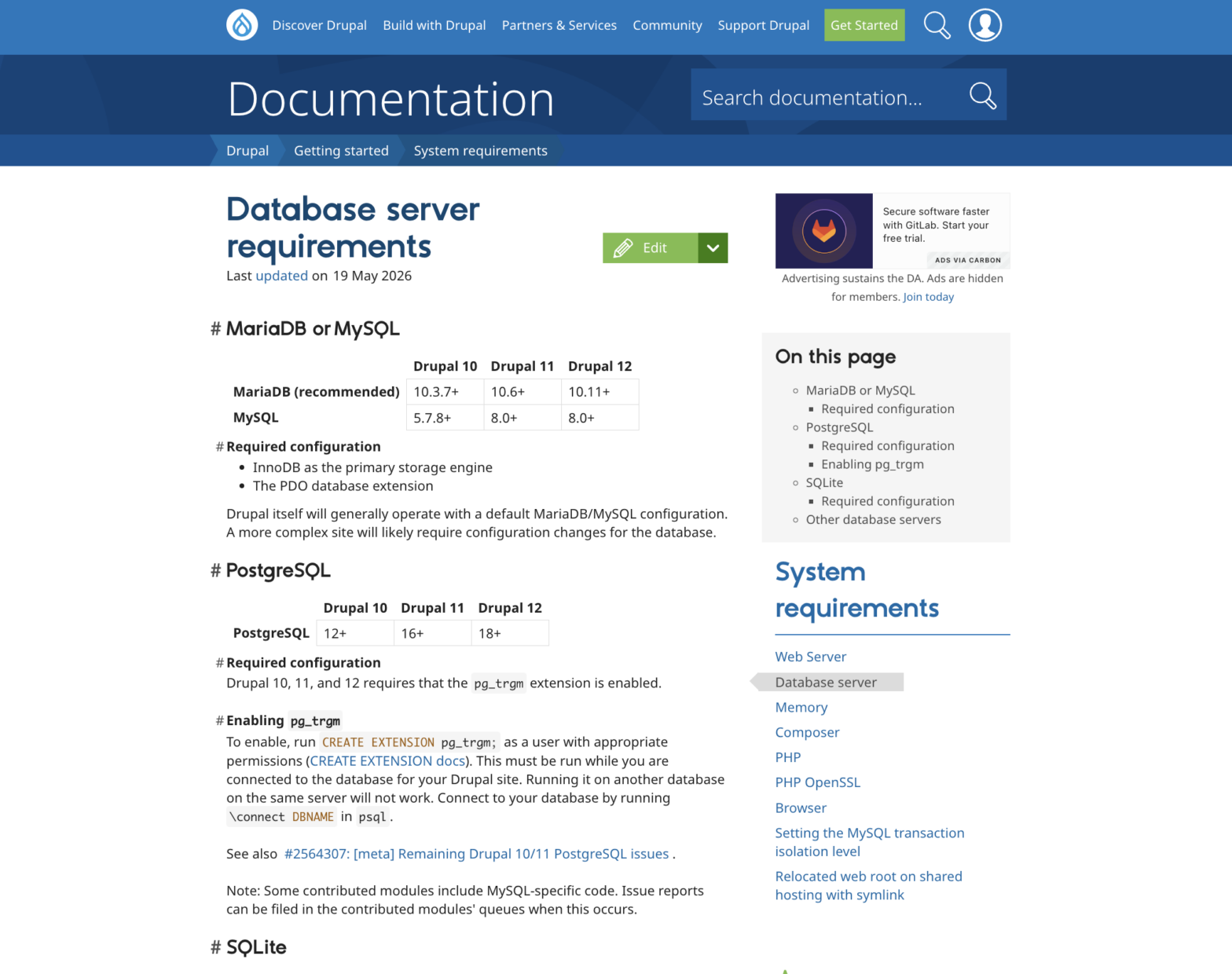
MariaDB is now clearly listed as the recommended database in Drupal’s official documentation. Following community discussion on Drupal.org, the Database server requirements now lists MariaDB first, and identifies it as the recommended database for Drupal 10, 11, and 12. Drupal is a major open source content management system—a flexible platform used by a substantial share of websites globally.
We’re glad to see this. Recognition matters because MariaDB is often used but documented as MySQL, going unnoticed under the hood—and when it goes unnamed, the work behind it loses visibility, a point Anna Widenius made in “I Am Not Building Cadillacs Anymore“, on how Henry Ford was long mistaken for the company that took his designs and became Cadillac.
…
If you ever considered contributing code to the MariaDB server, you should know that this is an intricate process involving multiple steps and multiple actors. To help you see your contributions successfully merged into the MariaDB Server codebase I’ve compiled a comprehensive description of the contribution process itself, the roles involved into it, the sequence of actions and conditions for transition from one to another. There’s even a diagram!
Please go to COMMUNITY_CONTRIBUTIONS.md.
This of course is going to be a moving target! I fully intend to keep the document up to date and enhance it with clarifications and process changes as they happen.
…
Continue reading “Documented: The MariaDB Server (Community) Contribution Process”

Inspired by my VERY long presentation on the topic at FOSDEM26 I thought I’d say a couple of words on how the contribution process works.
Contributing changes to MariaDB server is easy because it follows industry best practices: it’s using “normal” GitHub pull requests. Note that I’m working for the MariaDB Foundation. As such, “normal” for me is doing everything in the open, for everybody to see and participate. And all of the communication around the contribution (including the code review) is happening in that same pull request and is public. Until the intended end of the process: merging the pull request into the repository.
…
Continue reading “The MariaDB contribution process: a step by step guide.”

We are delighted to welcome QUAPE, a Singapore-based leader in high-performance hosting and IT infrastructure, as a Silver Sponsor of the MariaDB Foundation.
Founded in 2006, QUAPE provides enterprise-grade hosting solutions for businesses across Asia and beyond — from dedicated servers and VPS platforms to cybersecurity and custom software development. Their long-standing focus on reliability, speed, and scalable infrastructure mirrors the values we uphold within the MariaDB ecosystem.
One of the core responsibilities of the Foundation is to maintain and advance the MariaDB buildbot infrastructure: the continuous integration system that tests every change, validates every platform, and keeps MariaDB Server stable for millions of users worldwide.
…
Continue reading “QUAPE Joins the MariaDB Foundation as a Silver Sponsor”

The ideation phase of the MariaDB-Python Hackathon wrapped up on Sunday — and the response was phenomenal!
A huge thanks to everyone who joined the journey: from the BangPypers’ meetup announcement to the AMA webinars, from registration on HackerEarth to the final idea submissions — your creativity and energy made this phase a success!
We have been evaluating idea submissions as they have dropped in, with a final big push now after the deadline – we even brought AI into the loop to help out. The deadline was extended by a few days by popular demand, and to accommodate the local Indian holidays.
…
Continue reading “Impressive stats from ideation phase of Bengaluru Python hackathon, now closed”

The MariaDB Python Hackathon is gaining impressive traction! Following our AMA session (Ask Me Anything) on Friday, September 5th, we’ve seen even more encouraging engagement. Here’s where we stand and what we’re looking for as the idea submission phase continues until the end of September.
Strong Community Engagement
The response has been energizing, so far:
- Over 2,300 registrations from developers, from India and elsewhere
- 1,600+ teams formed and actively collaborating
- Steady stream of quality ideas being submitted
AMA webinar
Our AMA webinar on September 5th drew 164 unique viewers to a short summary of the hackathon and a productive Questions and Answers session.
…
Continue reading “MariaDB Python Hackathon: Building Momentum with Quality Idea Submissions”

{kind=link}
We are thrilled to welcome Scarf as a Gold Sponsor of the MariaDB Foundation!
Scarf’s commitment to improving open source distribution and visibility aligns closely with our mission to ensure the continued openness, innovation, and sustainability of MariaDB Server. As a platform that helps open-source projects understand and grow their user base, Scarf brings unique value to the ecosystem—not just through sponsorship, but through actionable insights that benefit the broader community.
For the MariaDB Foundation, understanding who uses MariaDB—and how, where, and why—is key to making better decisions. Scarf’s privacy conscious analytics help us move beyond assumptions and anecdotes, giving us real-world data to guide our outreach, improve our documentation, tailor our events, and strengthen our developer ecosystem.
…
Continue reading “Scarf Joins as Gold Sponsor of the MariaDB Foundation”