Tag Archives: MariaDB

We are thrilled to welcome Scarf as a Gold Sponsor of the MariaDB Foundation!
Scarf’s commitment to improving open source distribution and visibility aligns closely with our mission to ensure the continued openness, innovation, and sustainability of MariaDB Server. As a platform that helps open-source projects understand and grow their user base, Scarf brings unique value to the ecosystem—not just through sponsorship, but through actionable insights that benefit the broader community.
For the MariaDB Foundation, understanding who uses MariaDB—and how, where, and why—is key to making better decisions. Scarf’s privacy conscious analytics help us move beyond assumptions and anecdotes, giving us real-world data to guide our outreach, improve our documentation, tailor our events, and strengthen our developer ecosystem.
…
Continue reading “Scarf Joins as Gold Sponsor of the MariaDB Foundation”
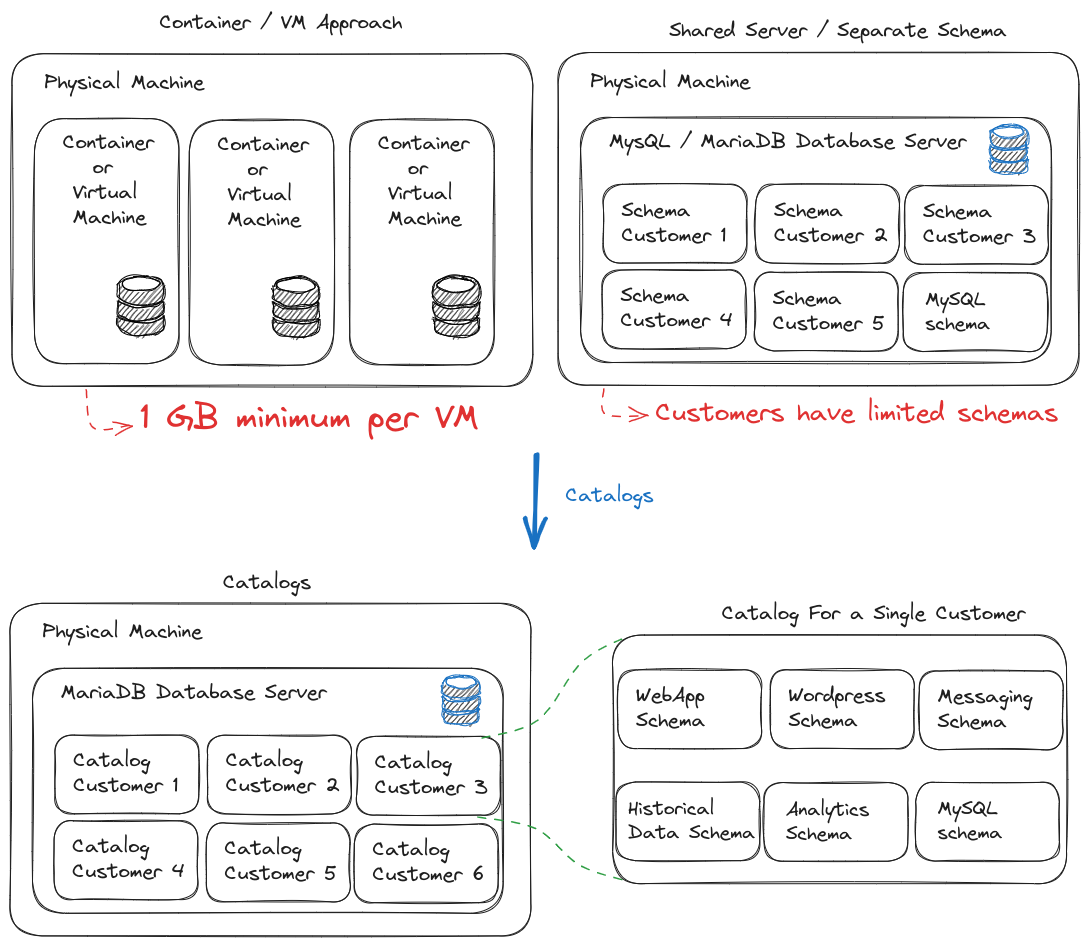
We’ve made significant progress on MariaDB Catalogs, and while there’s still work to be done, we’re excited to offer the community an easy way to try out our preview release. You no longer need to compile the source code yourself—just use our prebuilt containers, now available on our official quay.io development registry.
The code is available publicly on Github, in a separate repo compared to the official MariaDB Server (until the feature gets published as part of an official MariaDB Server release)
Documentation is available on the Knowledge Base.
…
Continue reading “MariaDB Catalogs preview containers available”
The following post was written by Stefano Petrilli, who contributed UUIDv4 and UUIDv7 implementations to MariaDB. Thank you, Stefano!
The original version of the Universal Unique IDentifiers (UUID), which is now known as UUIDv1, made his first appearance in the 1980s. The most interesting guarantee that they provide is the generation of IDs that are always unique across space and time.
To comply with this promise, it uses a combination of three elements:
- The node, which is a field that identifies the machine that generated the UUID.
…
As Chief Development Officer of the MariaDB Foundation, I’ve worked to ensure that our development efforts focus where they matter most. On this final day of 2024, I want to reflect on the significant technical achievements we’ve accomplished and the collaborative processes that made them possible.
Our work this year has been driven by the goal of building a stronger, more engaged MariaDB community. By sharing our progress and learnings, I hope to provide insights that may inspire and support other open-source projects.
Finally, I’ll outline the Foundation’s vision for 2025 and how we plan to bring it to life.
…
On November 6 2024 I presented a talk with the title: “The implementation of MariaDB parallel replication” at a local TeqHub meetup in Copenhagen.
In the talk I first presented how MariaDB replication works overall. I then described the central idea of optimistic parallel replication. Finally I described three details of the implementation: transaction scheduling; conflict detection; and efficient commit ordering. Here are the slides for the presentation.
I was very impressed by the level of the engagement of the audience. There were many questions that showed not only a deep interest in the subject, but also a deep understanding of the material I presented.
…
Continue reading “Talk: The implementation of MariaDB parallel replication”

Update 2024-10-15: The event has been cancelled in favour of something better. Please see the end of this post.
On the 24th – 25th October 2024 we will be hosting our first-ever Hackathon as part of our larger MariaDB Foundation presence around Open Source India.
What is a Hackathon?
If you have never done one before, it is basically a fun and challenging technology event where the goal is to create new things. Attendees are split into small teams of 5-10 people. An open source project is chosen to create and/or improve upon, and you have a day to work on it (and night as well if you really want to).
…
Continue reading “Announcing the first MariaDB Hackathon – in India!”

We’re here, we’re open source, and we have RDBMS based Vector Search for you! With the release of MariaDB 11.6 Vector Preview, the MariaDB Server ecosystem can finally check out how the long-awaited Vector Search functionality of MariaDB Server works. The effort is a result of collaborative work by employees of MariaDB plc, MariaDB Foundation and contributors, particularly from Amazon AWS.
Previously on “MariaDB Vector”
If you’re new to Vector, this is what’s happened so far:
- We blogged a number of times about our view of where Gen AI belongs in MariaDB Server
- We showed a first demo in February at our FOSDEM Fringe Event
- We launched a project page on mariadb.org/projects/mariadb-vector/, containing a number of videos
- We went on stage at Intel Vision in London, with AI everywhere
- We blogged about Amazon’s take on Vectors and MariaDB, in “MariaDB is soon a vector database, too“
The main point: MariaDB Vector is ready for experimentation
…
{kind=link}
On the 3rd of July, two weeks ago, I created a poll to ask about the future of feature development branches in MariaDB Server. Specifically, whether we should switch to a rolling model which is more familiar to users of services such as GitHub.
The votes we received gave a very clear result. Today I will share the conclusions we drew, as well as setting expectations for what will happen next.
Recap: what is this “main” branch all about?
In a rolling model, there is one main branch of the tree that all the feature commits go into (typically called “main”), and this is then forked when it is time to prepare a major release.
…
Continue reading “MariaDB Server GitHub branches: Moving to “main””